
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 코드잇 TIL
- 경사하강법
- 코딩
- 유학생
- 런던
- 코드잇
- SQL
- 나혼자코딩
- 영국석사
- for반복문
- 선형회귀
- 파이썬
- 판다스
- 다항회귀
- 행렬
- 로지스틱회귀
- 코딩공부
- 데이터분석
- 오늘도코드잇
- sql연습문제
- 코드잇TIL
- matplotlib
- 코딩독학
- 결정트리
- 윈도우함수
- CSS
- 머신러닝
- Seaborn
- HTML
- numpy
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 평균 제곱 오차 (MSE) 본문

1. 좋은 가설 함수 찾기
가설 함수는 아래와 같은 형태로 생겼습니다.
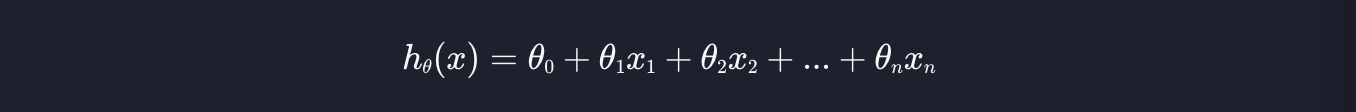
최대한 단순하게 예시를 들기 위해 입력 변수가 딱 하나 있다고 가정해 봅시다.

집 크기를 가지고 집 값을 예측하려고 하면, 입력 변수 x가 집 크기입니다.
아래와 같은 데이터들이 주어졌다고 가정해봅시다. 여기에 딱 맞는 가설 함수를 찾아봅시다.
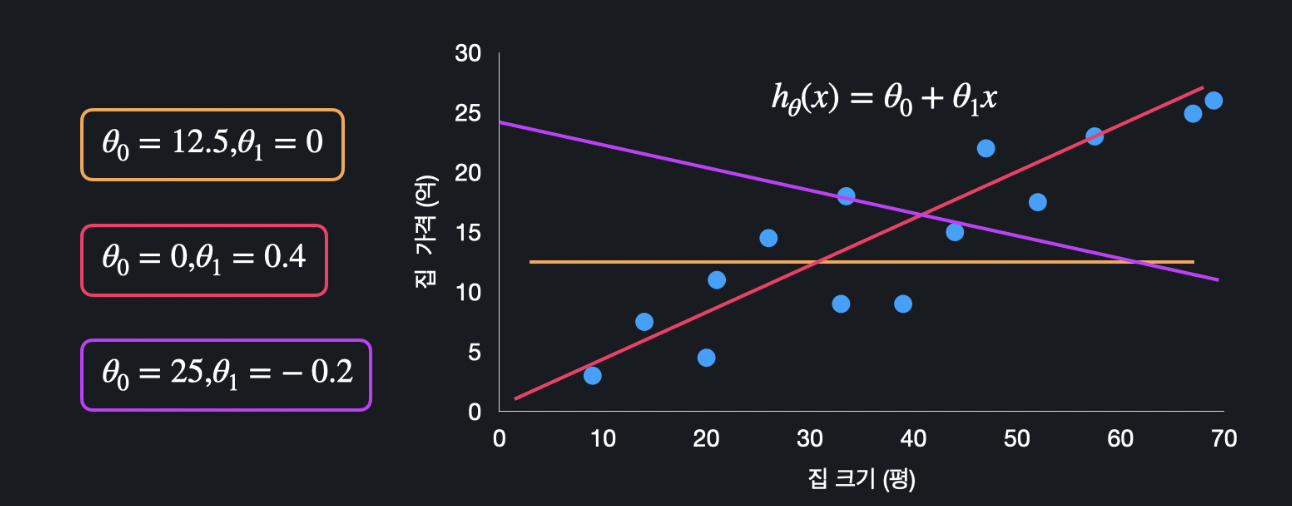
이렇게 세 개의 가설 함수가 있는데, 어떤 함수가 이 데이터셋에 가장 적합할까요? 눈으로 보면 주황색과 보라색 보다는 분홍색이 제일 잘 맞는 것 같은데 어떤 기준을 두고 비교하는게 좋을까요?
2. 평균 제곱 오차
선형 회귀에서 가장 많이 쓰는 가설 함수가 얼마나 좋은지 평가하는 방법은 평균 제곱 오차(mean squared error) 입니다. 앞 글자만 따서 MSE라고도 합니다. 이 평균 제곱 오차라는 것은 이 데이터들과 가설 함수가 평균적으로 얼마나 떨어져 있는지 나타내기 위한 하나의 방식입니다.
아래와 같이 데이터가 있고 가설 함수가 있으면 이 데이터들이 각각 이 선에서 어느 정도씩 벗어납니다. 즉, 각 데이터의 실제 값과, 이 가설 함수가 예측하는 값이 조금씩 차이가 납니다.
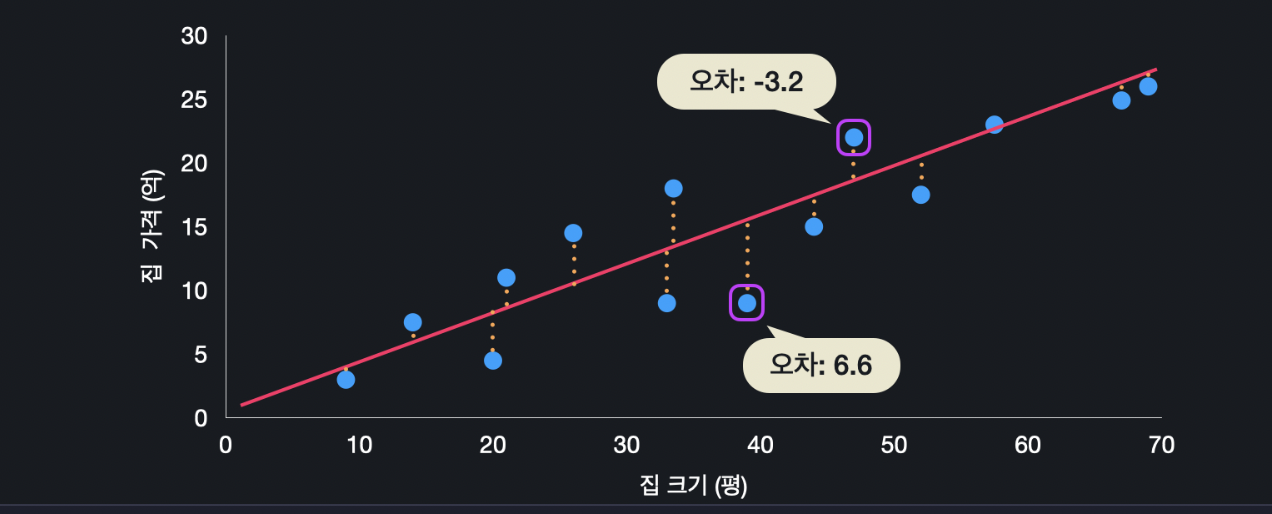
집의 크기 47평을 가설 함수에 넣으면 집 값이 18.8억으로 예측됩니다. 하지만 이 집의 실제 가격은 22억 입니다. 오차는 예측 값에서 원래 값을 뺀 것이니 -3.2가 됩니다.
집의 크기 39평을 가설 함수에 넣으면 가격이 15.6억으로 예측되는 데, 실제 가격은 9억입니다. 그러면 오차가 6.6억 입니다. 이런 식으로 오차를 다 구할 수 있는데, 이 오차값들을 모두 제곱합니다. 그리고 제곱한 값들을 더합니다. 그리고 이것의 평균을 내기 위해 총 데이터 개수 만큼 나누면 됩니다.
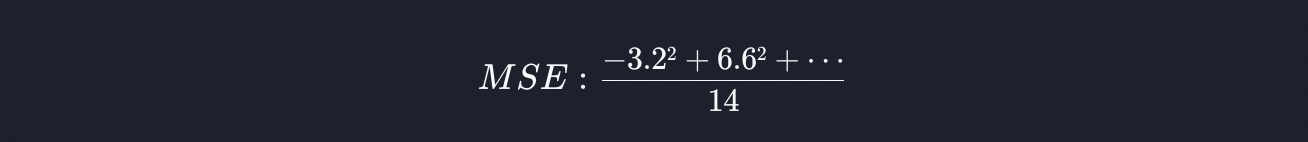
평균 제곱 오차가 크다는 건 가설 함수와 데이터들 간의 오차가 크다는 것이고, 결국 그 가설 함수는 데이터들을 잘 표현해 내지 못한 겁니다.
3. 제곱을 하는 이유
제곱을 하는 이유에는 두 가지가 있습니다.
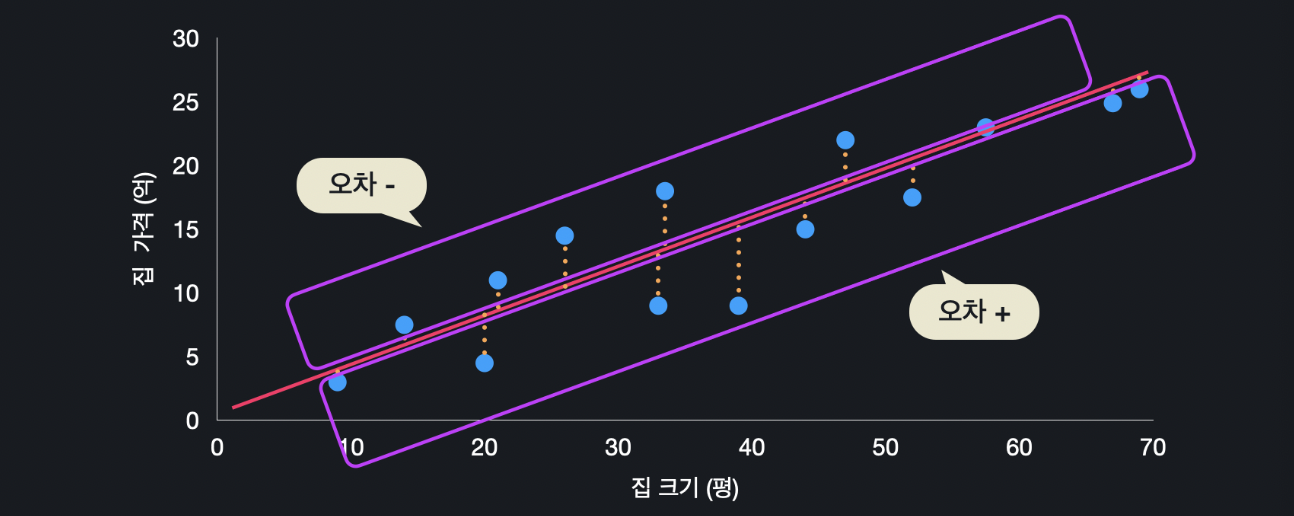
첫 번째 이유는 위의 오차를 계산하면 양수일 때도 있고 음수일 때도 있습니다. 우리는 이 차이가 양수 5든 음수 -5든 간에 똑같이 취급해야 합니다. 제곱을 하면 음수도 양수로 바뀌기 때문에, 양수로 통일을 할 수 있습니다.
오차에 제곱을 하는 두 번째 이유는 오차가 커질수록 더 부각시키기 위해서입니다. 만약 오차가 2면 제곱을 했을 때 4이고, 오차가 10이면 제곱을 했을 때 100입니다. 오차는 8밖에 차이가 안나지만, 제곱을 하면 96이 차이가 나는 건데 더 큰 오차에 대해서는 더 큰 패널티를 주기 위해서입니다.
4. 평균 제곱 오차 일반화
위에서 설명한 평균 제곱 오차를 일반화해서 수학적으로 표현하면 아래와 같습니다.
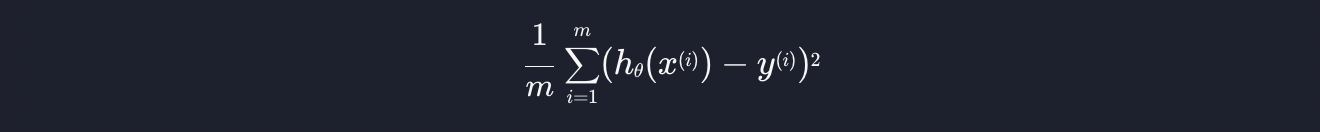
하나씩 살펴보면,
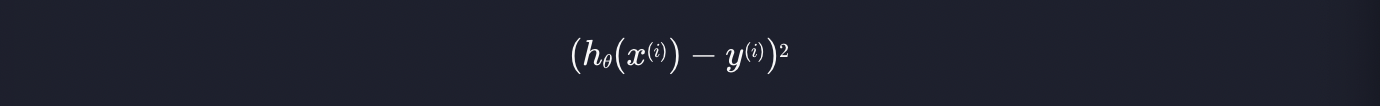
여기서 h는 가설 함수입니다. 그리고 x는 인풋, y는 아웃풋 입니ek. x(i)는 i번째 인풋, y(i)는 i번째 아웃풋을 뜻하는 것입니다. 집 가격 예측 프로그램을 예시로 들면, x(i)는 i번째 집의 크기이고, y(i)는 i번째 집의 가격입니다.
가설 함수 h에 x(i)를 넣었으니 x(i)에 대한 예측값이 나옵니다. 여기서 y(i)를 빼면, 이 가설 함수가 예측하는 값과 실제 데이터 값의 오차를 구할 수 있습니다. 그리고 그 오차값을 제곱한 것입니다.
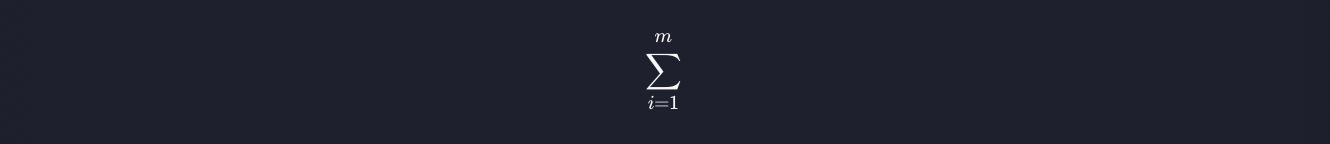
이것은 시그마로 i에 1부터 m까지 반복적으로 대입해서 더하라는 것입니다. 따라서
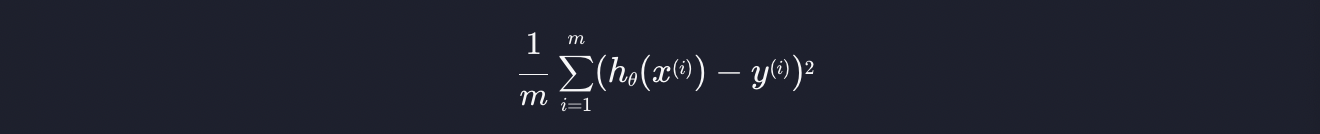
게산된 값들을 총 개수인 m으로 나눠주면 됩니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 경사 하강법 계산 (0) | 2023.07.11 |
|---|---|
| (Machine Learning) 손실 함수 (loss function) (0) | 2023.07.11 |
| (Machine Learning) 선형 회귀 가설 함수 (0) | 2023.07.10 |
| (Machine Learning) 선형 회귀 (Linear Regression) (0) | 2023.07.10 |
| (Machine Learning) 다변수 함수의 미분, 편미분 (0) | 2023.07.06 |



