
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Seaborn
- matplotlib
- sql연습문제
- 파이썬
- HTML
- 윈도우함수
- 영국석사
- 코딩독학
- 판다스
- 다항회귀
- 데이터분석
- 런던
- for반복문
- 코드잇TIL
- SQL
- 선형회귀
- 경사하강법
- 코딩공부
- 나혼자코딩
- CSS
- 행렬
- numpy
- 결정트리
- 머신러닝
- 코드잇
- 코딩
- 코드잇 TIL
- 오늘도코드잇
- 유학생
- 로지스틱회귀
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 편향(Bias)과 분산(Variance) 트레이드 오프(Tradeoff) 본문
(Machine Learning) 편향(Bias)과 분산(Variance) 트레이드 오프(Tradeoff)
life-of-nomad 2023. 9. 18. 09:18
머신 러닝 모델이 정확한 예측을 못하는 경우가 많습니다. 이런 문제를 어떻게 해결하는지 알아보겠습니다.
1. 편향
사람의 키를 이용해서 몸무게를 예측하고 싶다고 해봅시다.
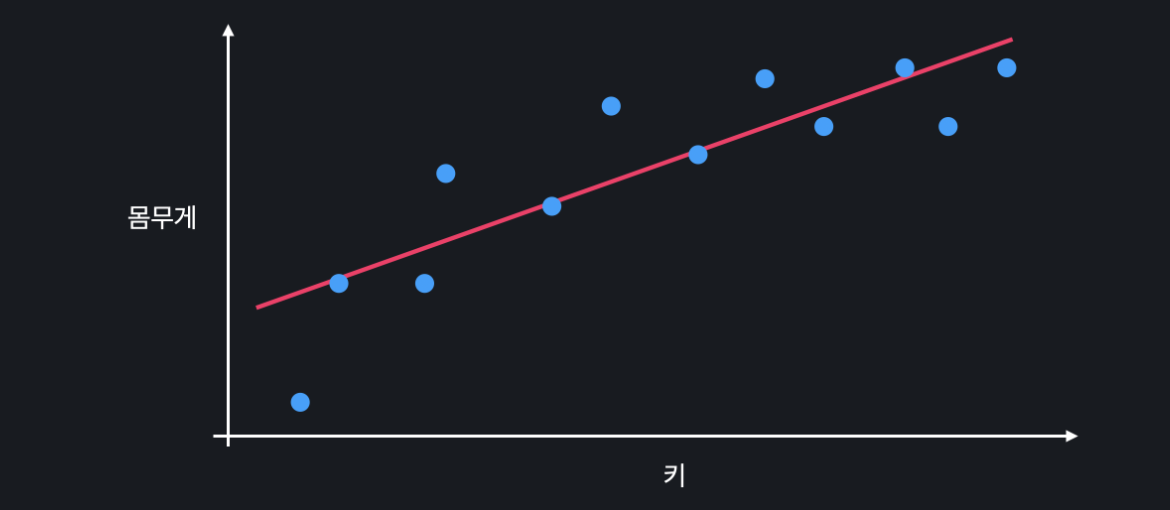
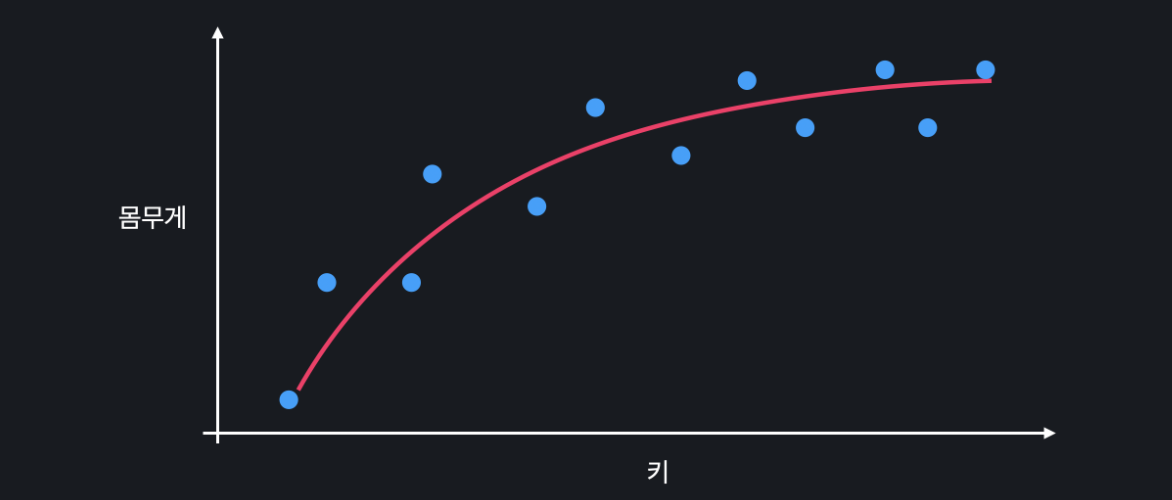
선형 회귀를 사용해서 training 데이터에서 위와 같은 관계라고 해봅시다. 위의 선이 과연 몸무게와 키의 관계를 잘 표현하고 있을까요? 뒤의 데이터를 살펴보면 어느 정도까지는 키가 늘어날 때 몸무게가 같이 늘어나지만, 일정 키 부터는 몸무게가 잘 안 늘어납니다. 따라서 아래와 같은 곡선이 데이터를 더 정확하게 표현합니다.
처음에 본 직선 모델의 문제는 모델이 너무 간단해서 아무리 학습을 해도 위와 같은 곡선 관계를 나타내지 못한다는 것입니다. 모델에 한계가 있는 것입니다. 모델이 너무 간단해서 데이터의 관계를 잘 학습하지 못하는 경우 모델의 편향이 높다고 합니다.
편향이 작은 모델을 살펴 봅시다.

이번에는 높은 차항의 회귀를 사용해서 위와 같은 관계를 학습했다고 해봅시다. 이 복잡한 곡선은 training 데이터에 거의 완벽히 맞춰져 있습니다. 모델의 복잡도를 늘려서 training 데이터의 관계를 잘 학습할 수 있도록 한 것입니다. 따라서 이 모델은 편향이 낮은 모델이라고 할 수 있습니다.
그러면 편향이 낮은 모델은 항상 편향이 높은 모델보다 좋을까요? training 데이터의 관계를 완벽하게 나타내는 모델이 있으면 마냥 좋다고만 생각할 수 있는데 꼭 그렇지만은 않습니다.
2. 분산
위의 직선 모델과 복잡한 곡선 모델을 이용해서 처음 보는 test데이터의 몸무게를 예측해본다고 합시다.

왼쪽은 training 데이터, 오른쪽은 test 데이터입니다.
평균 제곱 오차를 사용해서 모델의 성능을 평가할 건데 먼저 복잡한 곡선 모델부터 봅시다.
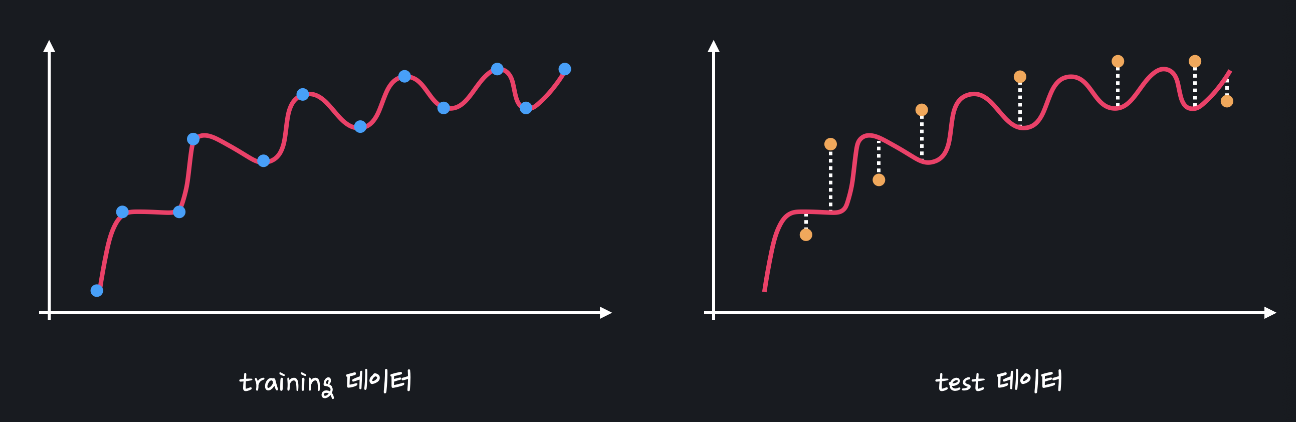
이 모델은 training 데이터에 대해서는 거의 완벽한 성능을 보이지만 test 데이터에 대해서는 상당히 안 좋은 성능을 보입니다. 모델이 오히려 너무 복잡해서 문제가 생깁니다. 모델이 training 데이터를 가지고 학습할 때 키와 몸무게의 관계를 배우기 보다는 아예 데이터 자체를 외워버리기 때문에 처음 보는 데이터 셋에 모델을 적용해보면 성능이 아주 떨어지는 것입니다.
데이터 셋 별로 모델이 얼마나 일관된 성능을 보여주는 지를 분산, 영여로는 variance라고 합니다. 다양한 데이터 셋 간에 성능 차이가 많이 나면 분산이 높다고 하고, 성능이 비슷하면 분산이 낮다고 합니다. 복잡한 곡선 모델은 데이터 셋마다 성능 차이가 많이 나니까 분산이 높은 것입니다.
직선 모델을 보겠습니다.

training set을 사용했을 때랑, test set을 사용했을 때 성능에 큰 차이가 없습니다. 다양한 데이터 셋을 사용해도 일관된 성능을 보인다는 것인데 따라서 직선 모델은 분산이 작습니다.
- 편향이 높은 머신 러닝 모델은 너무 간단해서 주어진 데이터의 관계를 잘 학습하지 못합니다.
- 편향이 낮은 모델은 주어진 데이터의 관계를 아주 잘 학습합니다.
- 첫 번째 직선 모델은 편향이 높고, 두 번째 복잡한 곡선 모델은 편향이 낮습니다.
- 분산은 다양한 테스트 데이터가 주어졌을 때 모델의 성능이 얼마나 일관적으로 나오는지를 뜻합니다.
- 직선 모델은 어떤 데이터 셋에 적용해도 성능이 비슷하게 나오지만, 복잡한 곡선 모델은 데이터 셋에 따라 성능의 편차가 크기 때문에 직선 모델은 분산이 작고, 곡선 모델은 분산이 큽니다.
3. 편향-분산 트레이드오프 (Bias-Variance Tradeoff)
일반적으로 편향과 분산은 하나가 줄어들수록 다른 하나는 늘어나는 관계가 있습니다. 둘 중 하나를 줄이기 위해서는 다른 하나를 포기해야 한다는 말입니다. 그렇기 때문에 이 관계를 편향-분산 트레이드오프라고 부릅니다.
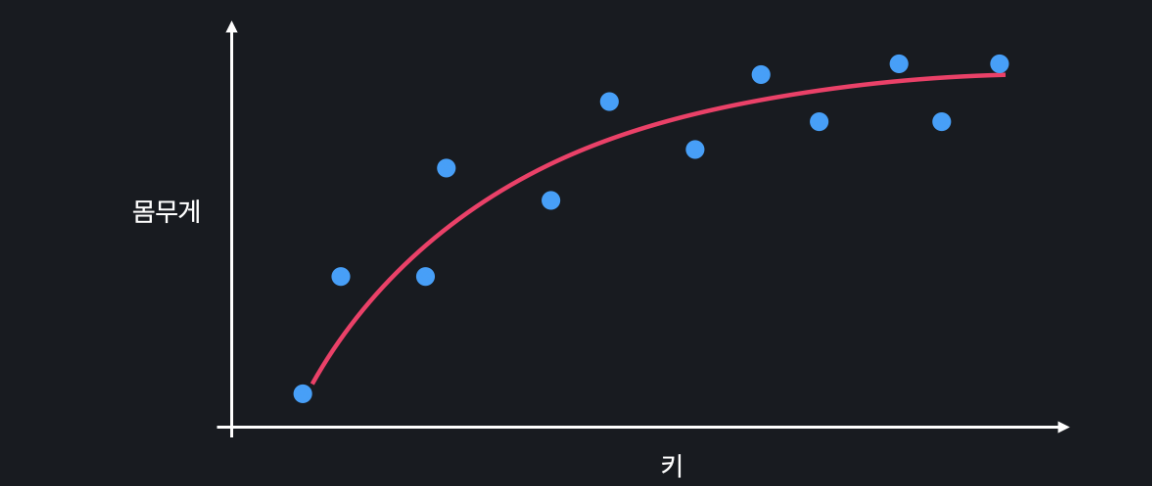
편향-분산 트레이드오프 문제는 머신 러닝 프로그램들의 성능과 밀접한 관계가 있기 때문에 편향과 분산, 다르게는 과소적합과 과적합의 적당한 밸런스를 찾아내는 것이 중요합니다. 아래와 같은 딱 적당한 곡선을 찾아야 한다는 것입니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) k-겹 교차 검증 (0) | 2023.09.21 |
|---|---|
| (Machine Learning) L1, L2 정규화 (Regularization) (0) | 2023.09.20 |
| (Machine Learning) one-hot encoding (0) | 2023.09.18 |
| (Machine Learning) Feature Scaling 과 경사하강법 (0) | 2023.09.15 |
| (Machine Learning) Feature Scaling: Normalization (0) | 2023.09.15 |



