
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 결정트리
- matplotlib
- 코딩독학
- 런던
- 다항회귀
- 코드잇
- 로지스틱회귀
- SQL
- 나혼자코딩
- 파이썬
- 오늘도코드잇
- 코딩공부
- 데이터분석
- for반복문
- 선형회귀
- 행렬
- sql연습문제
- 윈도우함수
- 코드잇 TIL
- 코딩
- 영국석사
- 머신러닝
- 판다스
- 경사하강법
- Seaborn
- 유학생
- 코드잇TIL
- CSS
- HTML
- numpy
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) Feature Scaling: Normalization 본문
(Machine Learning) Feature Scaling: Normalization
life-of-nomad 2023. 9. 15. 10:08
머신 러닝에서 많이 쓰이는 데이터 전처리 과정을 살펴보겠습니다. '데이터 전처리'란 주어진 데이터를 그대로 사용하지 않고 조금 가공해서 머신 러닝 모델을 학습시키기 더 좋은 형식으로 만들어 주는 것입니다.
1. Feature Scaling
feature scaling은 "feature, 입력 변수의 크기를 scale, 조정해준다" 라는 뜻입니다. 머신 러닝 모델에 사용할 입력 변수들의 크기를 조정해서 일정 범위 내에 덜어지도로 바꿔주는 것입니다.

위의 예시처럼 연봉이라는 입력 변수가 있고 나이라는 입력 변수가 있다고 가정해봅시다. 사람의 연봉은 보통 몇천만원 하지만 사람의 나이는 몇 살 밖에 안됩니다. 이렇게 입력 변수의 규모 단위가 너무 차이가 나면 머신 러닝에 방해가 될 수 있기 때문에 feature scaling을 해서 입려 변수들의 크기가 모두 일정 범위 내에 들어오도로 조정해주는 것입니다. feature scaling을 하면 경사 하강법을 조금 더 빨리 할 수 있습니다.
feature scaling 을 하는 방법은 여러 가지가 있는데 그중 가장 직관적인 'min-max normalization'이라는 방법에 대해 알아보겠습니다.
2. Min-Max Normalization
여기서 쓰이는 normalization은 '숫자의 크기를 0과 1사이로 만든다' 라는 뜻입니다. 데이터의 minimum 즉 최솟값, maximum 즉 최댓값을 이용해서 데이터의 크기를 0과 1사이로 바꿔주는 방법이기 때문에 min-max normalization이라고 불립니다. 공식은 아래와 같습니다.
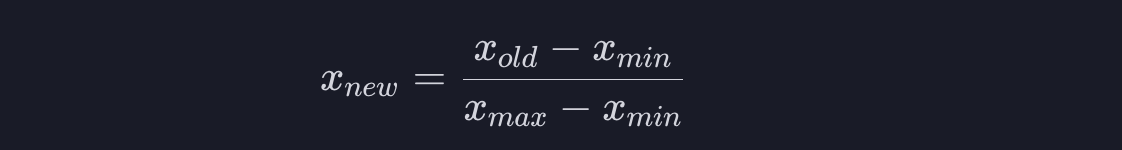
여기서 Xnew는 normalizaion을 한 데이터, Xold는 normalization을 하기 전 데이터, Xmax는 데이터의 최댓값, Xmin은 데이터의 최솟값을 의미합니다. 즉, "새로운 값은 최댓값 빼기 최솟값 분에 원래 값 빼기 최솟값" 이라고 할 수 있습니다.

이런 식으로 사람들의 키를 센티미터로 나타내는 데이터 열이 있다고 해보겠습니다. 먼저 이 열에서 가장 큰 값과 가장 작은 값을 찾아냅니다. 위의 경우 210과 140입니다. 이 두값의 차이는 40입니다.
그 다음에는 키 열에 있는 모든 데이터에서 최솟값을 빼고, 이걸 최댓값에서 최솟값을 뺀 값, 70으로 나눠줍니다. 첫 번째 데이터는 180이니까 normalization을 해주면 0.57이 나옵니다.
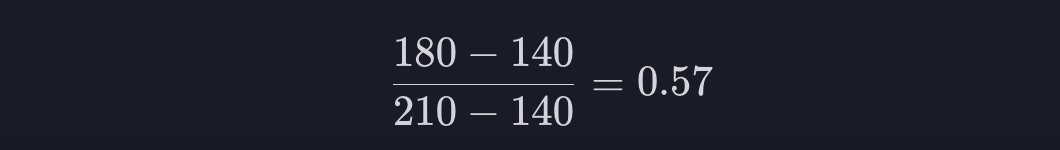
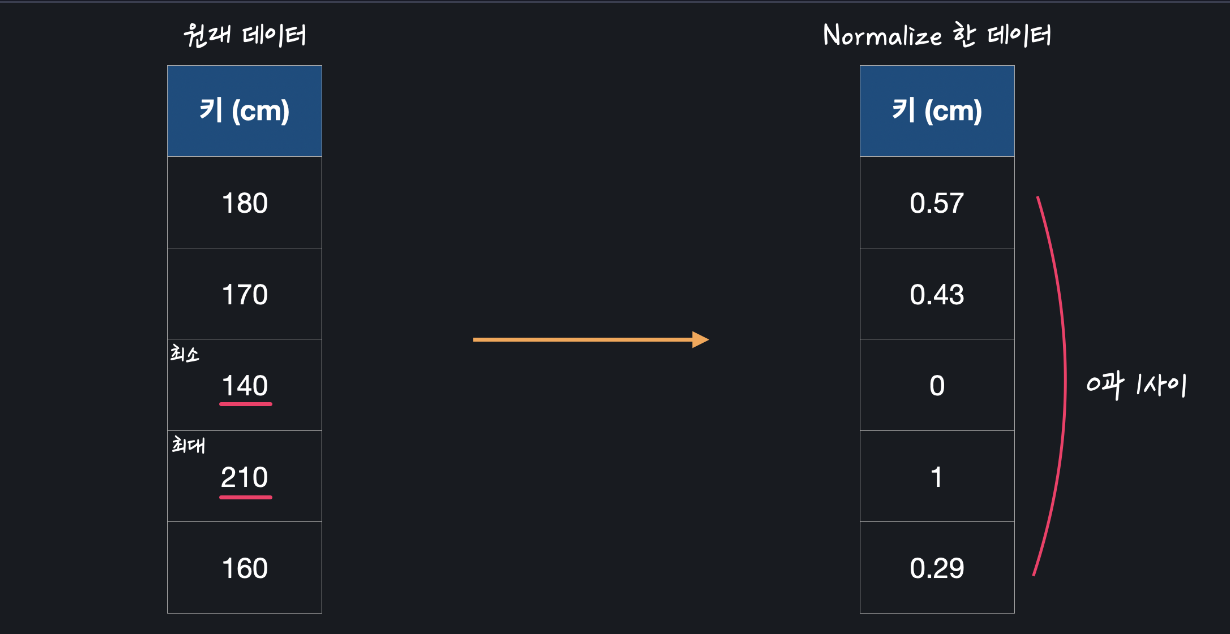
이런 식으로 normalization을 해주면 항상 0과 1사이의 값이 나옵니다. 이유는 간단합니다. 데이터의 최솟값이 140, 최댓값이 210이라는 말은 모든 데이터의 값이 140과 210사이에 있다는 뜻입니다. 그럼 그 사이에 있는 어떤 값에서 140을 빼주면 0에서 70사이의 숫자가 나오고 그 숫자를 210-140=70으로 나눠주면 0과 1사이의 숫자가 나옵니다.
이렇게 normalization을 하면 모든 데이터 값을 0과 1사이의 작은 숫자로 바꿀 수 있습니다. 즉, 입력 변수 feature을 0과 1사이 범위의 숫자들로 크기 조정, scaling해주는 것입니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) one-hot encoding (0) | 2023.09.18 |
|---|---|
| (Machine Learning) Feature Scaling 과 경사하강법 (0) | 2023.09.15 |
| (Machine Learning) 로지스틱 회귀 구현하기 (0) | 2023.09.13 |
| (Machine Learning) 로지스틱 회귀 경사 하강법 (0) | 2023.09.13 |
| (Machine Learning) 로지스틱 회귀 로그 손실, 손실 함수 (0) | 2023.09.13 |



