
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 다항회귀
- numpy
- 코딩공부
- 윈도우함수
- 머신러닝
- 나혼자코딩
- 코드잇TIL
- 코딩
- SQL
- 런던
- 데이터분석
- 행렬
- 결정트리
- 코드잇 TIL
- matplotlib
- 유학생
- 영국석사
- Seaborn
- for반복문
- sql연습문제
- 경사하강법
- 오늘도코드잇
- 판다스
- HTML
- 파이썬
- 로지스틱회귀
- CSS
- 코드잇
- 코딩독학
- 선형회귀
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 에다 부스트 알고리즘, 스텀프 본문

1. 데이터 셋
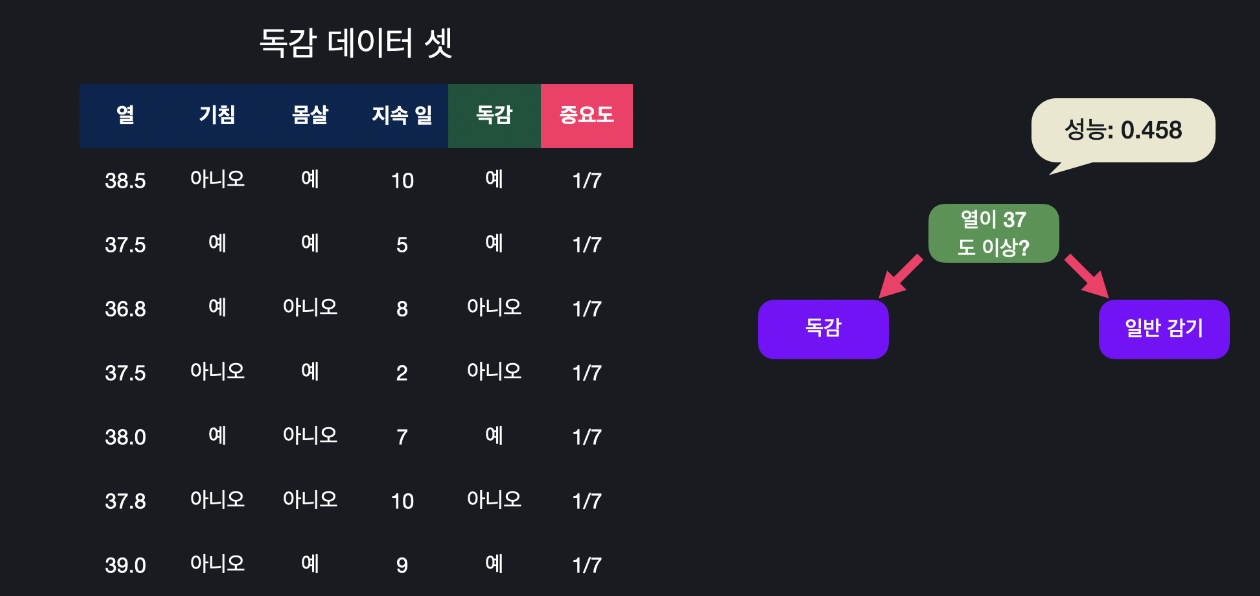
저번 글에서 사용한 데이터에다가 중요도라는 열을 추가하겠습니다. 에다 부스트는 전에 있는 스텀프들이 틀리게 예측한 데이터들을 조금 더 잘 맞추려고 하는 알고리즘입니다. 그렇기 때문에 스텀프를 만들 때 전에 예측에 실패했던 데이터들을 조금 더 중요하게 취급을 해야 합니다. 이걸 수치화하고 보기 편하게 열로 추가시켜주는 것입니다. 처음에는 틀리게 예측한 데이터가 없으니까 모든 데이터의 중요도를 같게 설정합니다. 7개의 데이터가 있으니까 각각 1/7씩 입니다. 중요도의 합은 항상 1로 유지시켜 줍니다.
2. 첫 스텀프 만들기
첫 스텀프는 전에 만든 스텀프가 없기 때문에 결정 트리를 만들 때랑 똑같이 root 노드를 고릅니다.
일단 각 질문들의 지니 불순도를 계산합니다. 지니 불순도가 가장 낮은, 즉 가장 성능을 좋게 하는 질문을 기준으로 정합니다.
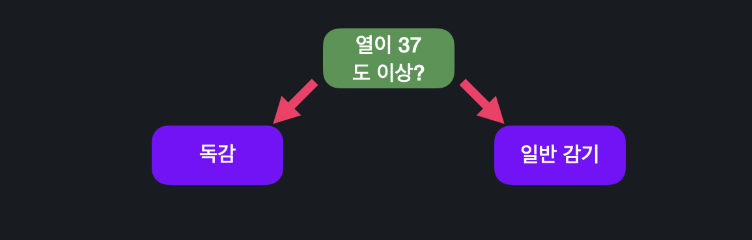
'37.5도가 넘나요?'가 가장 좋다고 해봅시다. 스텀프는 질문이 하나밖에 없으니까 넘으면 독감 환자, 아니면 일반 감기 환자로 분류합니다.
3. 스텀프 성능 계산하기
이렇게 첫 번쨰 스텀프를 만들었습니다. 에다 부스트는 예측을 종합할 때 각 트리의 성능을 반영합니다. 그렇기 때문에 트리를 만들 때마다 미리 성능을 계산해야 합니다. 특정 스텀프의 성능을 계산하는 방법은 아래와 같습니다.

여기서 total_error은 잘못 분류한 데이터들의 중요도의 합입니다. 지금 열 37.5를 기준으로 나눴을 때 두 개의 데이터가 틀렸습니다. 이 데이터의 중요도는 각각 1/7씩 이니까 여기서 total_error은 이 두 값을 더한 값 2/7입니다.
계산한 total_error 2/7를 식에 넣으면 0.458이 나옵니다. 이게 바로 이 스텀프의 성능인 것입니다. 왜 이 식을 사용하는지 아래를 봅시다.

total_error가 1에 가까워질수록 작아지고, 0에 가까워질수록 커집니다.
total_error가 1이면, 모든 데이터의 중요도 합이 1이니가 스텀프가 모든 데이터를 다 틀리게 예측한 경우입니다. 이때는 성능이 엄청 안 좋은거기 때문에 성능을 무한하게 작게 만듭니다.
반대로 total_error가 0이면, 스텀프가 모든 데이터를 다 맞게 예측하는 경우입니다. 이 스텀프의 성능은 엄청 좋은 거니까 성능을 무한히 크게 만들어줍니다.
total_error가 딱 0.5면, 갖고 있는 데이터 중 딱 반은 맞고 반은 틀린건데 그러면 성능이 아무 의미가 없으니까 0으로 만들어 줍니다. 잘 맞출수록, 또는 잘 못 맞출수록 성능을 기하급수적으로 늘리고 줄여줍니다.
정리하자면
- 스텀프는 결정 트리를 만들 때랑 똑같이 지니 불순도를 이용해서 만듭니다.
- 모든 데이터는 중요도라는게 있습니다. 이 글에서는 스텀프의 오류, total_error를 계산할 때 사용했습니다. total_error는 틀리게 예측한 모든 데이터 중요도의 합입니다.
- 이 total_error는 스텀프의 성능을 계산하는데 사용됩니다.
4. 데이터 중요도 바꾸기
첫 스텀프를 만들고, 성능을 계산하는걸 봤습니다. 이번에는 틀리게 예측한 데이터의 중요도는 높여주고, 맞게 예측한 데이터의 중요도는 줄여주는 방법을 보겠습니다.
첫 번째 스텀프는 열이 '37.5도가 넘나요?' 였고, 성능은 0.458 이었습니다. 그리고 각 데이터의 중요도는 다 똑같이 1/7이었습니다.
첫 스텀프를 만들 때는 모든 데이터가 똑같은 중요도를 줬는데 다음에 만들 스텀프는 앞에서 틀리게 예측한 데이터를 더 잘 분류해야 합니다. 이걸 데이터의 중요도를 통해서 합니다. 중요도가 높은 데이터를 더 잘 맞추게 할 거니까 틀리게 분류한 데이터의 중요도는 늘려주고, 맞게 분류한 데이터의 중요도는 낮춰줘야 합니다.
먼저 틀리게 분류한 모든 데이터에 대해서는 아래와 같이 중요도를 바꿔줍니다.
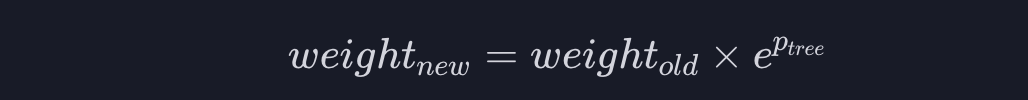
왼쪽 weight는 새로운 중요도고 오른쪽weight는 예전 중요도, e는 무리수, Ptree는 스텀프의 성능입니다.
제대로 분류한 모든 데이터에 대해서는 아래와 같이 계산 합니다.

여기 ePtree를 그래프로 표현하면 스텀프의 성능이 커질수록 커지고 작아질수록 작아지고, e-ptree를 보면 스텀프의 성능이 작아질수록 커지고 커질수록 작아지는 걸 확인할 수 있습니다.
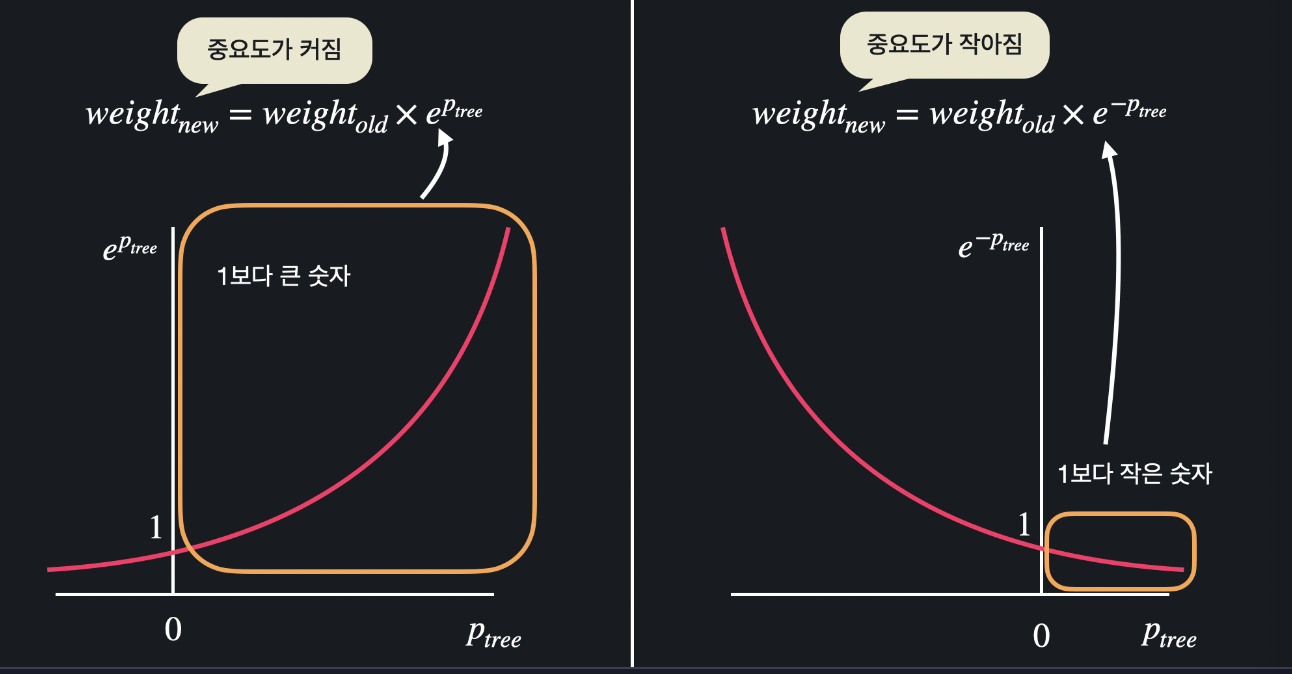
둘 다 성능이 0일때 1이 나옵니다. 스텀프가 데이터를 반 이상만 맞추면 틀린 데이터는 원래 중요도에 1보다 큰 값을 곱하니까 원래 값보다 커지고 맞은 데이터는 원래 중요도에 1보다 작은 값을 곱하니까 원래 값보다 작아지게 됩니다.
아래의 데이터를 보면 모든 데이터의 무게가 1/7입니다. 그리고 이 스텀프의 성능은 0.458이라고 했으니까 이걸 각 데이터 무게에 적용하면 새로운 무게를 구할 수 있습니다.
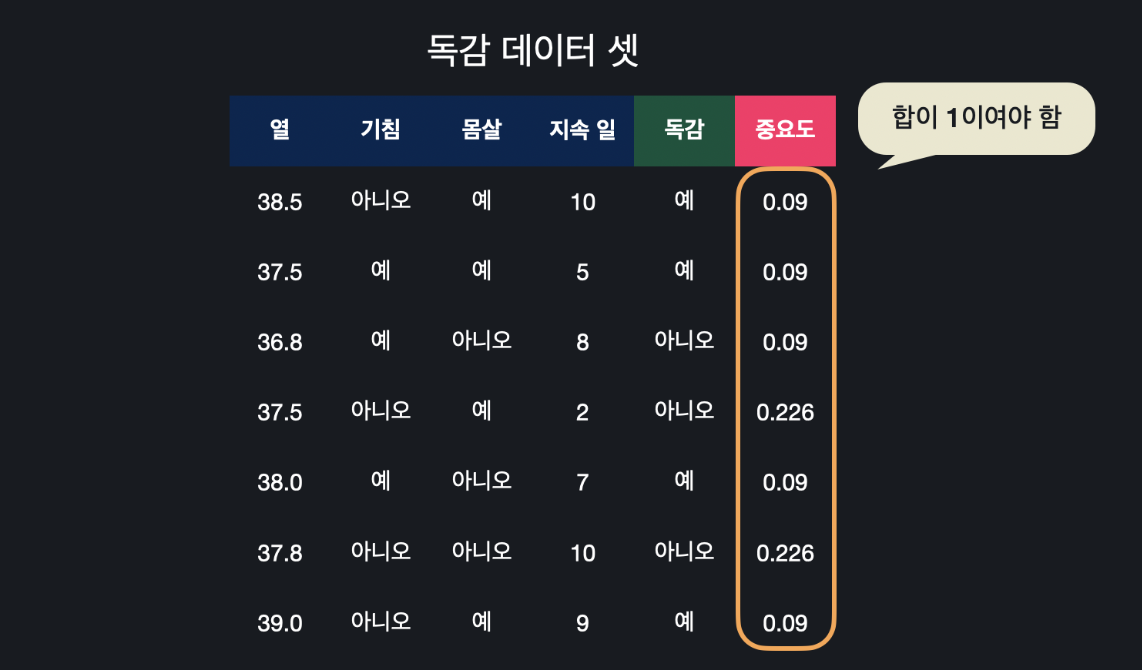
틀린 데이터들의 중요도는 이제 0.226, 맞게 분류한 데이터들의 중요도는 0.090이 된 걸 확인할 수 있습니다. 그리고 중요도는 항상 다 더해서 1입니다. 지금은 다 더하면 1보다 작으니까 비율적으로 조절해줘야 합니다. 이 때는 모든 데이터의 중요도를 더해주고, 각 데이터의 중요도를 이 값으로 나눠주면 됩니다. 소수점은 조절해줍니다.
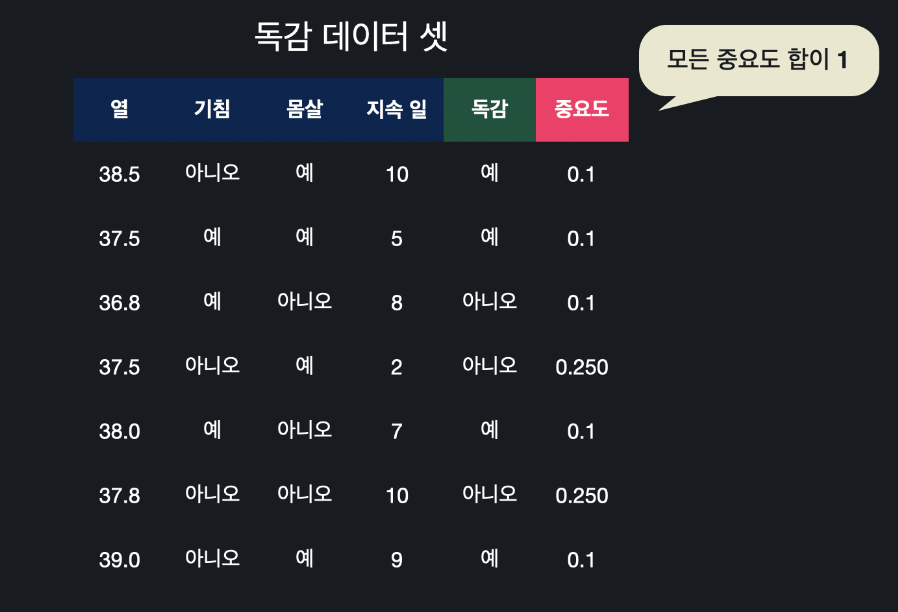
잘못 분류했던 이 두 데이터는 중요도가 0.250, 나머지 데이터들은 중요도가 0.100이 됩니다. 틀린 데이터의 중요도는 높이고, 맞은 데이터의 중요도는 낮춘 것입니다. 모든 데이터의 중요도를 더하면 다시 1이 나오는 것을 확인할 수 있습니다.
이렇게 중요도가 바뀐 데이터 셋을 이용해서 다음 스텀프, 그다음 스텀프, 이런식으로 추가하는 방법에 대해 알아보겠습니다.
4. 새롭게 데이터 셋 만들기
bootstrapping이랑 비슷하긴 한데 임의로 만드는게 아니라 중요도를 이용해서 만들기 때문에 좀 다릅니다.
새로 만들 데이터 셋은 기존에 데이터 셋의 크기와 똑같은데 각 데이터의 중요도를 데이터 셋에 들어갈 확률로 만듭니다. 이걸 하기 위해 첫 데이터부터 중요도를 이용해서 범위를 정해줍니다.
맨 위데이터는 0부터 중요도 0.1만큼, 그다음 데이터는 0.1부터 중요도를 더한 0.2까자ㅣ, 그 다음은 0.2부터 0.3까지, 이런 식으로 범위를 줍니다. 그리고 0에서 1까지 아무 숫자를 고르는데 이 떄 나온 숫자를 갖는 범위의 데이터를 새로운 데이터에 추가해 줍니다. 예를 들어 0.4012를 고르면 이 데이터를 새 데이터 셋에 추가해주는 것입니다.
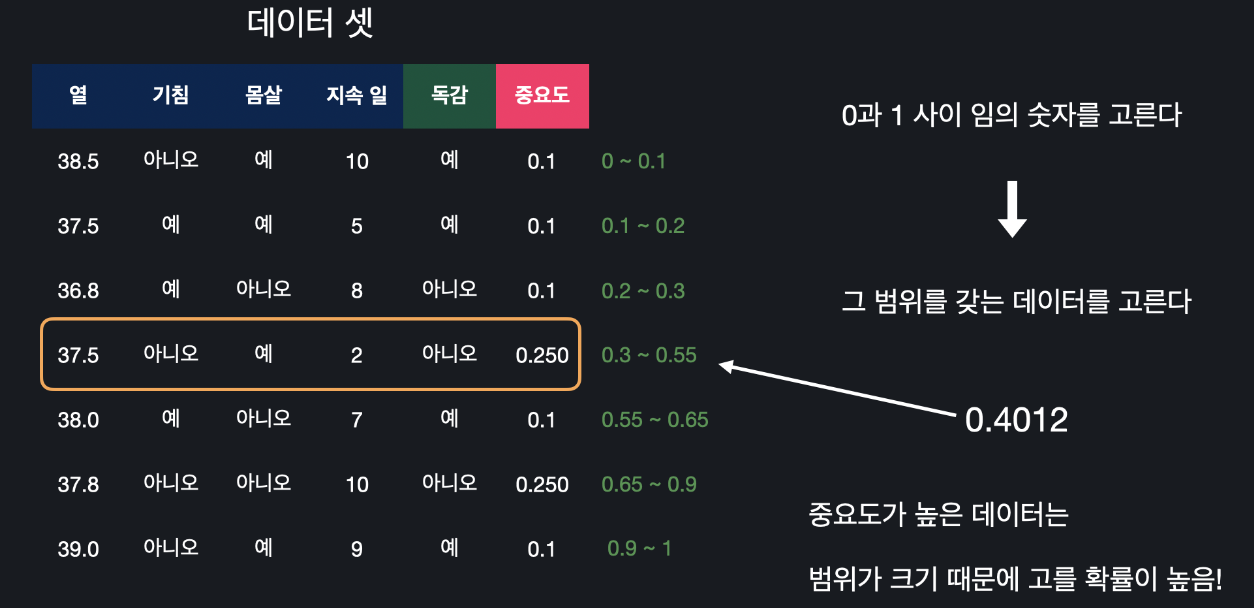
중요도가 높은 데이터는 범위도 크기 대문에 선택될 확률이 높습니다. 이걸 원래 데이터 셋의 크기만큼 반복합니다. 이렇게 새로운 데이터를 만듭니다.

이걸 살펴보면 중요도가 높은 데이터들은 여러 번 들어갔고 중요도가 낮은 데이터들은 아예 추가가 안 된 데이터도 있습니다. 처음부터 이 스텀프는 전 스텀프가 틀린 데이터들을 좀 더 잘 맞추게 만들려고 한 것이기 때문에 그렇습니다. 이 새로운 데이터 셋은 전 스텀프들이 틀린 중요도가 높은 데이터들이 확률적으로 더 많이 들어있기 때문에 더 잘 맞출 수 있는 것입니다.
이제 이 데이터 셋을 써서 첫 스텀프를 만들 때랑 똑같이 새 데이터 셋으로 스텀프를 만듭니다. 지니 불순도를 비교해서 가장 성능을 좋게 하는 기준을 정해주는 것입니다. 그리고 마찬가지로 이 스텀프의 성능을 계산합니다. 그리고 성능을 계산한 후에는 또 원래 데이터 셋에서 분류에 틀린 데이터들의 중요도를 높여주고, 맞은 데이터의 중요도를 낮춰줍니다.

정리해보자면,
- 전 모델이 틀리게 예측한 데이터의 중요도는 올려주고, 맞게 예측한 데이터의 중요도는 낮춰줍니다.
- 그 다음에는 데이터의 중요도를 써서 새로운 데이터 셋을 만듭니다.
- 새로운 데이터 셋으로 스텀프를 만듭니다. 이 스텀프의 성능을 계산합니다.
이렇게 해서 하나의 스텀프를 추가했는데, 그 다음부터는 계속 이 단계들을 반복해주면 됩니다.
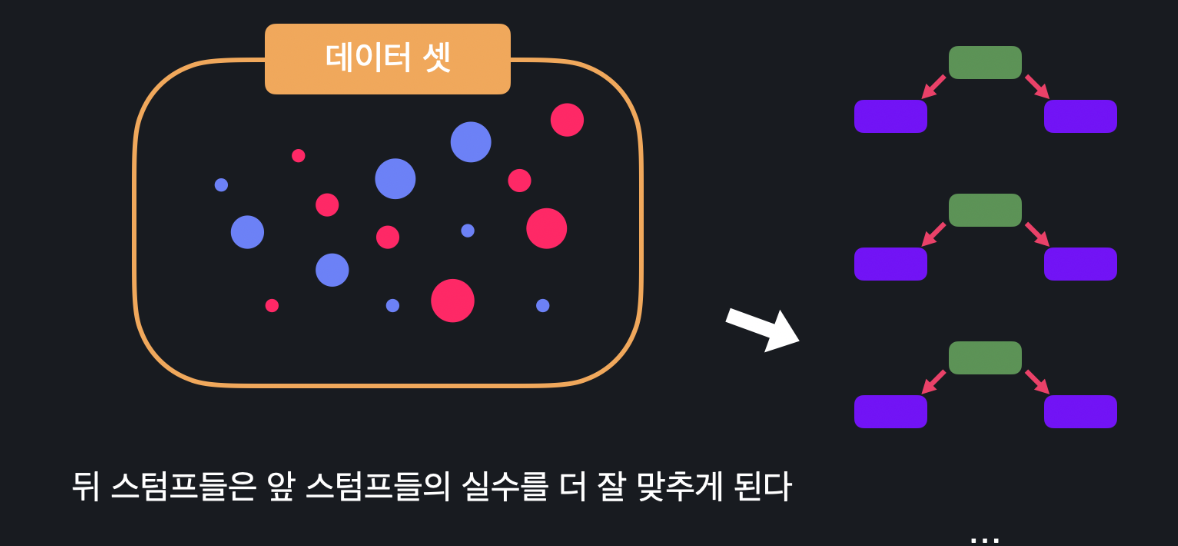
이런 식으로 스텀프를 만들면 첫 번째 스텀프가 틀리게 분류한 데이터들이 두 번째 스텀프가 좀 더 잘 맞출 수 있고, 세 번째 스텀프는 이 앞에 있는 스텀프들이 틀린 데이터를 좀 더 잘 맞출 수 있고, 이런식으로 스텀프들을 만들 수 있게 됩니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 내용 기반 추천 시스템, sklearn으로 유저 평점 예측하기 (0) | 2023.10.16 |
|---|---|
| (Machine Learning) 에다부스트(Adaboost) (1) | 2023.10.11 |
| (Machine Learning) 결정트리 랜덤 포레스트, Bagging (0) | 2023.10.10 |
| (Machine Learning) 결정 트리, 속성 중요도 (1) | 2023.10.08 |
| (Machine Learning) 결정트리, 지니 불순도 (gini impurity) (1) | 2023.10.05 |



