
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 로지스틱회귀
- 데이터분석
- SQL
- numpy
- 행렬
- for반복문
- CSS
- sql연습문제
- 유학생
- 코드잇
- 나혼자코딩
- 다항회귀
- 머신러닝
- Seaborn
- HTML
- 선형회귀
- 영국석사
- 경사하강법
- 오늘도코드잇
- 판다스
- matplotlib
- 코드잇TIL
- 윈도우함수
- 코드잇 TIL
- 코딩독학
- 결정트리
- 코딩공부
- 런던
- 코딩
- 파이썬
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 결정트리 랜덤 포레스트, Bagging 본문

랜덤 포레스트는 수많은 트리들을 임의로 만들고, 이 모델들의 결과를 다수결 투표로 종합해서 예측하는 모델입니다. 트리를 많이, 임의로 만들기 때문에 랜덤 포레스트라는 이름을 갖습니다.
랜덤 포레스트에서 임의성을 더하는 요소는 두가지가 있습니다. 그 중 Bootstrapping에 대해 알아보겠습니다.
1. Bootstrapping
bootstrapping은 갖고 있는 데이터 셋을 이용해서 조금 다른 데이터 셋을 만들어내는 방법입니다. 예를 들어 독감 환자 데이터를 사용한다고 해봅시다. 총 다섯 개의 열이 있는데 고열, 기침, 몸살, 콧물, 그리고 환자가 독감인지 아닌지에 대한 데이터가 있습니다.

이 데이터 셋을 이용해서 좀 다른 데이터 셋을 만들어야 합니다. 방법은 간단합니다. 그냥 원래 있던 데이터 셋에서 임의로 데이터를 갖고 와서 새 데이터 셋에 추가하면 됩니다.
가장 먼저 원래 데이터 셋에서 임의로 하나의 데이터를 고릅니다. 세 번째 행의 데이터를 선택해봅시다. 그리고 새로운 데이터 셋에 추가해 줍니다. 또 임의로 하나의 데이터를 고릅니다. 다섯 번째 행의 데이터입니다. 이것도 추가합니다. 이 과정을 반복합니다. 아래에 살펴보면 세 번째 행의 데이터가 두 번 추가됐고, 두 번째 행의 데이터는 한 번도 추가가 안됐습니다. 나머지는 다 한 번씩 추가됐습니다. 상관 없습니다. 그냥 원래 데이터를 기반으로 같은 크기의 데이터 셋을 임의로 만드는게 목적이였으니까요.
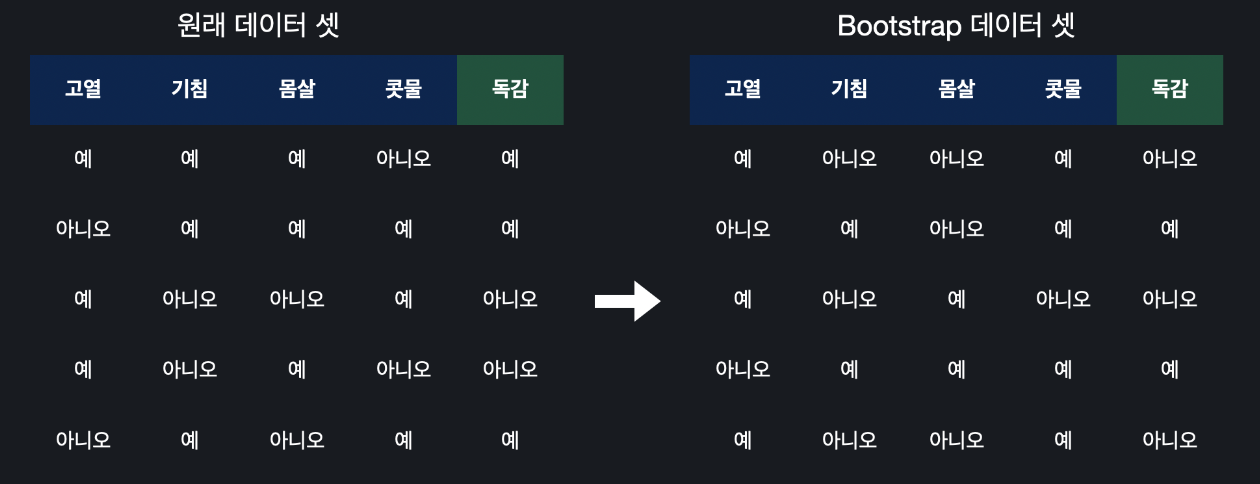
이런 식으로 원래의 데이터 셋에서 임의로 새로운 데이터 셋을 만들어내는 방법이 bootstrapping입니다. 그리고 이렇게 만들어낸 데이터 셋을 bootstrap 데이터 셋이라고 부릅니다.
2. bootstrapping 을 하는 이유
앙상블은 수많은 다른 머신 러닝 모델들을 만들고 이 모델들의 예측을 종합해서 예측을 하는 기법입니다. 모델들을 다 정확히 똑같은 데이터 셋으로 학습시키면 다양하게 결과가 나오는 대신 모든 모델을이 비슷한 결과를 낼 수도 있습니다.
이걸 방지하기 위한 한 가지 방법이 한 모델을 만들 때마다 다 똑같은 데이터 셋을 사용하는게 아니라, 임의로 만든 bootstrap 데이터 셋을 사용하는 겁니다.
3. Bagging
모든 앙상블 기법을 사용하는 모든 알고리즘들이 bootstrapping을 쓰는건 아닙니다. 이렇게 bootstrap 데이터 셋을 만들어 내고, 모델들의 결정을 종합해서 (aggregate) 예측을 하는 앙상블 기법을 bootstrap aggregating, 줄여서 bagging 이라고 합니다.
4. 임의로 결정 트리 만들기
위 방법을 이용해서 수많은 결정 트리들을 만들어봅시다. 결정 트리를 그냥 만들 때에는 각 속성들을 사용한 질문들의 지니 불순도를 구하고, 가장 낮은 것을 골라서 사용했었습니다. 그런데 랜덤 포레스트를 만들 때는 이 네 가지 속성 중 두 개를 임의로 고릅니다. 속성이 더 많으면 임의로 세 개나 네 개도 고를 수 있는데 여기서는 두 개라고 합니다. 고열과 기침을 사용한다고 해봅시다. 그 다음에는 이 두개의 불순도를 계산해서 둘 중 더 좋은 것으로 root 노드의 질문을 정합니다.

'고열이 있나요?'를 골랐다고 해봅시다. 그 다음에는 똑같이 2개의 기준을 임의로 골라서 그 중 지니 불순도가 낮은 것을 사용합니다.

결정 트리를 만드는 것 자체는 원래 방법과 크게 다르진 않은데 매 노드를 만들 때 임의로 만들기 때문에 수많은 서로 다른 결정 트리들이 나올 수 있습니다. 결정 트리 하나를 만들기 위해 한 걸 정리해보면,
- bootstrapping을 사용해서 임의로 데이트 셋을 만든다.
- 결정 트리를 만들 때도 질문 노드들을 어느 정도는 임의로 만들었다.
그 다음은 이 두 단계를 계속 반복합니다. 100번 정도라고 해봅시다. 그러면 서로 조금씩 다른 100개의 결정 트리를 만들 수 있습니다.
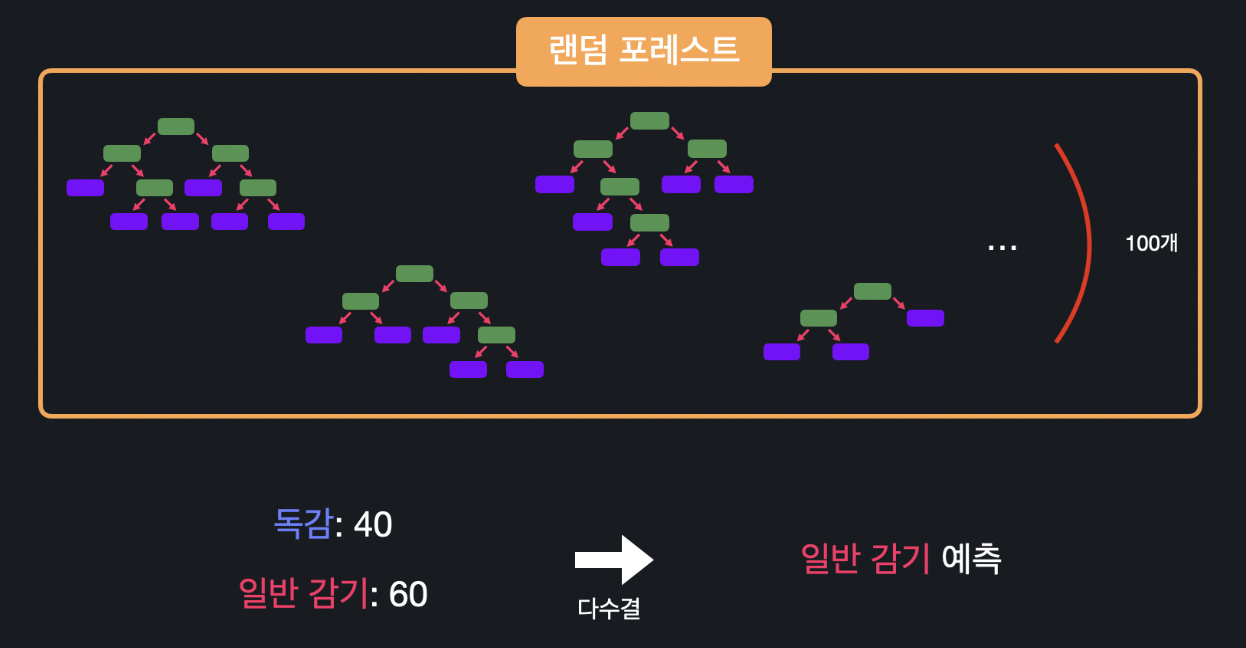
이런 식으로 bootstrap 데이터를 써서 많은 트리들을 임의로 만드는 게 바로 랜덤 포레스트 입니다. 랜덤 포레스트를 사용해서 예측을 할 때는 만들어놓은 트리들의 예측을 다수결 투표로 종합해서 결정합니다.
예를 들어서 데이터를 100개의 트리에 각각 넣습니다. 그리고 독감을 예측하는 트리의 수를 세면 40, 일반 감기를 예측하는 트리의 수는 60, 이런식으로 둘 중 많은 것인 일반 감기로 예측 값을 리턴합니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 에다 부스트 알고리즘, 스텀프 (2) | 2023.10.12 |
|---|---|
| (Machine Learning) 에다부스트(Adaboost) (1) | 2023.10.11 |
| (Machine Learning) 결정 트리, 속성 중요도 (1) | 2023.10.08 |
| (Machine Learning) 결정트리, 지니 불순도 (gini impurity) (1) | 2023.10.05 |
| (Machine Learning) 결정 트리, if-else문으로 구현하기 (1) | 2023.10.04 |



