
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- SQL
- 결정트리
- 코딩공부
- 다항회귀
- 선형회귀
- numpy
- 윈도우함수
- HTML
- 행렬
- 런던
- 영국석사
- for반복문
- 코드잇
- 데이터분석
- 나혼자코딩
- 로지스틱회귀
- 오늘도코드잇
- 파이썬
- matplotlib
- 코드잇 TIL
- CSS
- 머신러닝
- sql연습문제
- 유학생
- 판다스
- Seaborn
- 코딩독학
- 코드잇TIL
- 경사하강법
- 코딩
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 에다부스트(Adaboost) 본문

1. 스텀프
랜덤 포레스트를 만들 때와 똑같이 에다 부스트에서도 수많은 결정 트리들을 만듭니다. 랜덤 포레스트에서 만드는 트리들은 깊이가 조금 있었는데 에다부스트에서는 깊은 결정 트리들이 아니라 root 노드 하나와 분류 노드 두 개를 갖는 얕은 결정 트리를 만듭니다.

예를 들면 교통사고 데이터를 분류하고 싶다고 합시다. 뿌리 노드의 질문이 속도가 80km를 넘었는지 안 넘었는지, 그리고 넘었으면 사망, 넘지 않았으면 생존 이렇게 예측하는 단순한 트리인 입니다. 이런식으로 하나의 ㅈ리문과 그 질문에 대한 답으로 바로 예측을 하는 결정 트리를 나무의 그루터기를 의미하는 스텀프라고 합니다.
이런 식으로 스텀프를 만들게 되면 성능은 주로 50%보다 조금 나은 성능을 갖게 됩니다. Boosting 기법은 성능이 안 좋은 모델들, weak learner을 사용합니다. 그래서 이것에 맞게 일부러 일반 결정 트리가 아닌 스텀프만을 사용합니다.
2. 데이터 셋
Boosting 기법답게 각 모델이 사용하는 데이터 셋은 임의로 만들지 않습니다. 예를들어 봅시다.
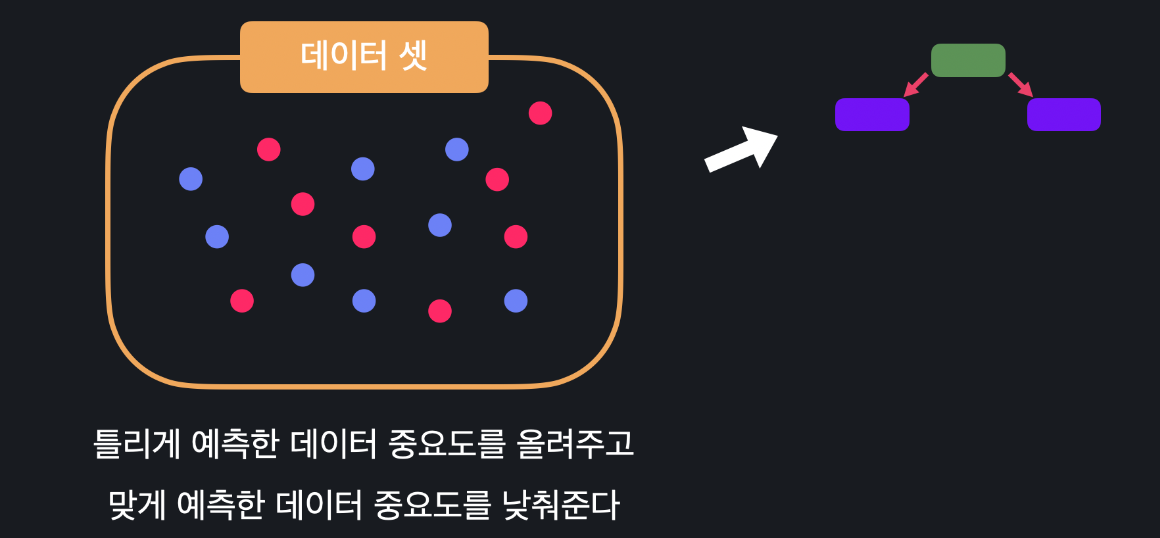
파란색과 빨간색 데이터는 서로 분류가 다른 데이터들입니다. 이걸 이용해서 결정 스텀프 하나를 학습했다고 합시다. 그럼 이 결정 스텀프가 맞게 분류하는 것들이 있고, 틀리게 분류하는 것들이 있습니다. 그럼 다음 스텀프의 데이터 셋을 만들 떄는 이 앞에 있는 스텀프가 틀린 것들의 중요도를 더 높여줍니다. 맞은 것들의 중요도는 낮춰줍니다.
중요도가 높은 데이터는 뒤에 만들 스텀프들이 더 우선적으로 맞출 수 있게 합니다. 낮은 데이터는 조금 덜 신경써줍니다. 이렇게 또 스텀프를 만듭니다. 그 다음에 스텀프를 만들 때도, 마찬가지로 데이터 셋에서 예측에 틀린 데이터와 맞은 데이터들의 중요도를 조절해서 바로 전에 예측에 틀렸던 데이터들을 좀 더 잘 예측하는 스텀프를 만듭니다.
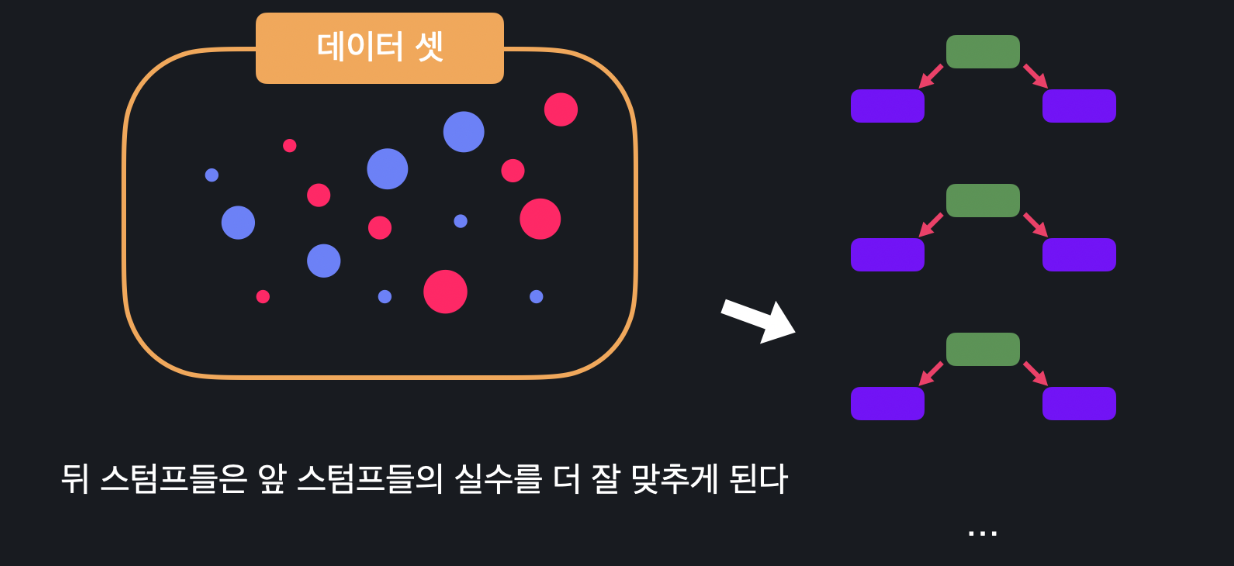
이런 식으로 각 스텀프는 전에 있던 스텀프들의 실수를 바로잡는 방향으로 만들어줍니다.
이걸 미리 정해놓은 만큼 반복해서 엄청 많은 스텀프들을 만들어주는 것입니다.
3. 예측
앙상블 기법을 사용하니까 이렇게 수많은 스텀프들을 만든 후에는 종합적인 예측을 해야합니다. 에다 부스트는 다수결의 원칙이 아니라 성능 주의적으로 예측을 합니다.
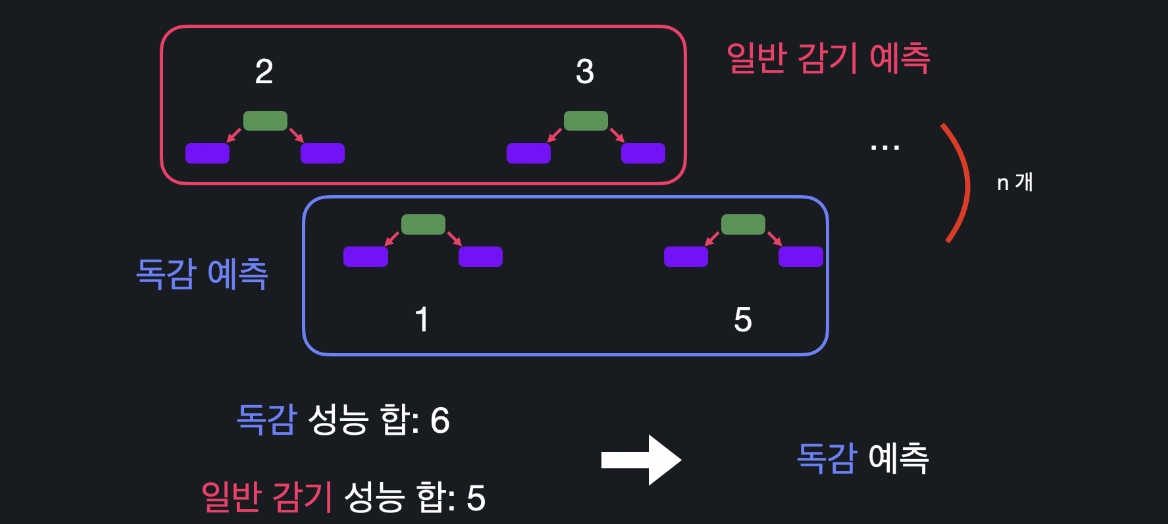
예를 들어 이 스텀프의 성능이 각각 2, 1, 3, 5, 라고 합시다. 그럼 이 네 스텀프가 최종 결정에 다른 영향력을 갖는다는 말입니다. 독감 학습 데이터에서 스텀프가 두 개가 독감을 예측하고 나머지 2개가 일반 감기를 예측했다고 합시다. 독감을 예측한 스텀프들의 성능의 합은 6이고 일반 감기를 예측한 스텀프들의 성능은 5입니다. 이때는 아무리 다수결이 2:2여도 더 성능의 합이 높은 결정에 따르는 것입니다.
따라서 에다 부스트는
1) 성능이 별로 좋지 않은 결정 스텀프들을 많이 만듭니다.
2) 스텀프를 만들 떄, 전 스텀프들이 예측에 틀린 데이터들의 중요도를 더 높게 설정해 줍니다.
3) 최종 결정을 내릴 때, 성능이 좋은 결정 스텀프들 예측 의견의 비중은 높고, 그렇지 않은 결정 스텀프의 의견의 비중은 낮게 반영됩니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 내용 기반 추천 시스템, sklearn으로 유저 평점 예측하기 (0) | 2023.10.16 |
|---|---|
| (Machine Learning) 에다 부스트 알고리즘, 스텀프 (2) | 2023.10.12 |
| (Machine Learning) 결정트리 랜덤 포레스트, Bagging (0) | 2023.10.10 |
| (Machine Learning) 결정 트리, 속성 중요도 (1) | 2023.10.08 |
| (Machine Learning) 결정트리, 지니 불순도 (gini impurity) (1) | 2023.10.05 |



