
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코드잇TIL
- 코드잇 TIL
- HTML
- SQL
- 코딩
- for반복문
- 머신러닝
- 오늘도코드잇
- Seaborn
- 행렬
- 유학생
- 데이터분석
- sql연습문제
- 선형회귀
- 파이썬
- 코드잇
- 다항회귀
- matplotlib
- 코딩독학
- CSS
- 로지스틱회귀
- 영국석사
- 결정트리
- 나혼자코딩
- 코딩공부
- 경사하강법
- 윈도우함수
- numpy
- 판다스
- 런던
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 로지스틱 회귀 로그 손실, 손실 함수 본문

선형 회귀에서 가설함수가 있었고, 선형 회귀를 통해 하려고 하는 건 학습 데이터에 최대한 잘 맞는 가설 함수를 찾는 것 입니다. 그러려면 가설 함수를 평가하는 어떤 기준이 있어야 하는데, 그 기준이 되는 게 손실 함수입니다.
로지스틱 회귀에서도 마찬가지 입니다. 데이터에 잘 맞는 가설 함수를 찾는 거고, 손실 함수를 이용해서 가설 함수를 평가하는 것입니다. 가설 함수랑 손실 함수가 좀 다르게 생겼을 뿐입니다.
로지스틱 회귀의 가설 함수는 아래와 같다고 지난 글에서 배웠습니다.

그럼 로지스틱 회귀의 손실 함수를 알아보겠습니다.
선형 회귀의 손실 함수는 평균 제곱 오차라는 개념을 기반으로 했습니다. 데이터 하나하나의 오차를 구하고, 그 오차들을 다 제곱해서 평균을 내는 작업을 했었습니다. 로지스틱 회귀의 손실 함수는 평균 제곱 오차를 사용하지는 않습니다. 대신 로그 손실(log loss)라는 걸 사용합니다. 다른 말로 cross entropy라고도 합니다.
1. 로그 손실
로그 손실이 무엇인지 알아봅시다. 로그 손실을 이용해서 로지스틱 회귀의 손실 함수를 만들어보겠습니다.
로그 손실은 아래와 같이 생겼습니다.
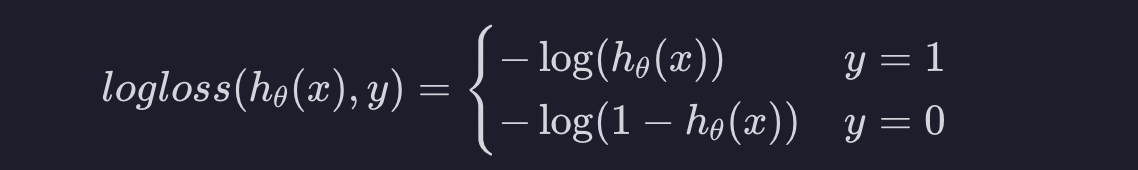

여기서 h(x)는 어떤 입력 변수에 대한 가설 함수의 예측값입니다. y는 실제 값입니다. 로그 손실 함수는 예측값이 실제 결과랑 얼마나 차이가 있는지 알려 주는 역할을 합니다.
그런데 로지스틱 회귀는 분류 알고리즘 이였습니다. 그리고 분류가 두 가지라고 가정하면, 가능한 목표 변수가 1과 0밖에 없습니다. 이 두 경우에 대해서 식이 조금 다른 것입니다. 실제 아웃풋이 1인 경우부터 알아봅시다.
1) 1인 경우
위의 왼쪽 그래프를 보면 h(x)가 1이면 100%의 확률로 아웃풋이 1일 것이라고 예측하는 것입니다. 실제 결과가 1이기 때문에 이 가설 함수는 완벽하게 맞춘 것입니다. 따라서 손실이 0입니다.
만약 h(x)가 0.8정도면 80% 확률로 아웃풋이 1일 거라고 예측하는 건데 실제 결과가 1이기 때문에 이 가설 함수는 꽤 잘했따고 평가할 수 있습니다. 손실이 좀 있긴 하지만 그렇게 크진 않습니다.
이 그래프를 보면 왼쪽으로 갈수록 손실이 커지는데 처음에는 슬슬 커지다가 급격하게 가파라집니다. h(x)가 1에서 멀어질수록 잘 못하고 있는 거니까 손실을 엄청나게 키우는 것입니다.
2) 0인 경우
실제 아웃풋이 0인 경우에 대해서 알아봅시다. 그러면 그래프가 거꾸로 되는 것 입니다. h(x)가 0이라는 건 아웃풋이 1일 확률이 0%라고 예측하는 건데 실제 결과가 0이기 때문에 완벽하게 예측했다고 할 수 있습니다. 그래서 손실이 0인 것입니다.
만약 h(x)가 0.2정도면 20% 확률로 아웃풋이 1일 것이라고 예측하는 것인데 실제 결과가 0이기 때문에 나쁘지 않게 예측했다고 할 수 있습니다. 그래서 손실이 있긴 하지만 크진 않습니다.
이 그래프는 오른쪽으로 갈수록 손실이 커지고 처음에는 슬슬 커지다가 그래프가 급격하게 가파라집니다. h(x)가 0에서 멀어질수록 못하고 있는 것이라서 손실을 엄청나게 키우는 것입니다.
2. 로지스틱 회귀 손실 함수
선형 회귀를 할 때는 평균 제곱 오차 개념을 이용해서 손실 함수를 만들었습니다. 그런 것처럼 로지스틱 회귀에서는 로그 손실 개념을 이용해서 손실 함수를 만들 것입니다. 위에서 배운 로그 손실을 이용해서 로지스틱 회귀의 손실함수를 만들어야 하는데 보통 로지스틱 회귀에서 로그 손실을 쓸 때는 아래와 같은 형태로 씁니다.

위에서 설명한 식과 같은 식입니다. 그 이유는 y에 1을 대입하면 오른쪽 항이 0이 되어서 사라지고, y=0을 대입하면 왼쪽 항이 0이 되어서 사라지기 때문입니다. 그렇게 한줄로 표현할 수 있습니다.
손실 함수를 구하는 방법은 각 데이터에 대해서 손실을 구한 후, 손실의 평균을 내는 것입니다.

위의 식을 간단히 설명하자면 모든 학습 데이터에 대해서 로그 손실을 계산하고, 더한 값의 평균을 내는 것 입니다. 그걸로 가설 함수를 평가하는 것입니다.
이 손실 함수의 인풋은 세타입니다. 왜냐하면 가설 함수는 세타 값들을 어떻게 설정하느냐에 따라 바뀌기 때문에 학습 데이터의 손실이 달라집니다.
또한, 이 부분에 로그 손실 함수를 완전히 대입하면 아래와 같은 식이 됩니다.

'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 로지스틱 회귀 구현하기 (0) | 2023.09.13 |
|---|---|
| (Machine Learning) 로지스틱 회귀 경사 하강법 (0) | 2023.09.13 |
| (Machine Learning) 로지스틱 회귀 결정 경계 (0) | 2023.09.12 |
| (Machine Learning) 로지스틱 회귀 (0) | 2023.09.12 |
| (Machine Learning) 분류 (0) | 2023.09.12 |



