
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 코딩
- 머신러닝
- pandas
- 코드잇 TIL
- 행렬
- sql연습문제
- 다항회귀
- 코딩공부
- matplotlib
- 경사하강법
- 선형회귀
- CSS
- 윈도우함수
- SQL
- 서브쿼리
- 나혼자코딩
- 메소드
- 결정트리
- Seaborn
- 코드잇
- 로지스틱회귀
- 오늘도코드잇
- 데이터분석
- 파이썬
- HTML
- for반복문
- 코딩독학
- 코드잇TIL
- numpy
- 판다스
- Today
- Total
Coding Diary.
(Machine Learning) 로지스틱 회귀 결정 경계 본문

저번 글에서 로지스틱 회귀를 하기 위해서는 가설 함수에 대하여 최적의 theta값을 찾아내야 한다고 하였습니다. 가설 함수의 결곽값은 주어진 데이터 x가 특정 분류(분류1)일 확률을 리턴합니다. 그렇기 때문에 h의 결괏값이 0.5 이상이면 1로, 0.5면 0으로 분류했었습니다.
1. 속성이 하나일 때
예를 들어 공부 시간으로 시험을 통과했는지 탈락했는지 예측하고 싶다고 해봅시다. 그럼 속성이 하나니까 아래와 같은 가설 함수가 있습니다.
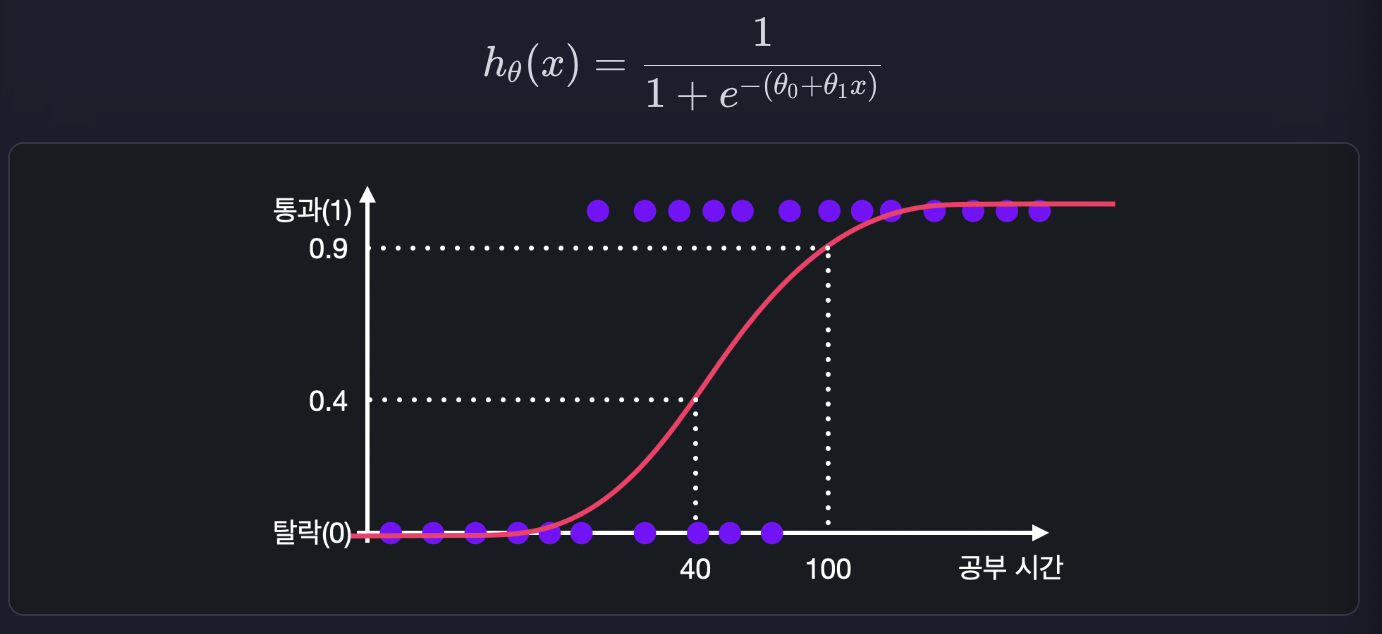
이렇게 x에 100시간을 넣어서 0.9가 나오면 100시간 공부한 학생이 시험을 통과할 확률은 90%인 거고, x에 40시간을 넣어서 0.4가 나오면 40시간 공부한 학생이 시험을 통과할 확률은 40%라고 해석할 수 있습니다. 그렇기 떄문에 가설 함수의 아웃풋이 0.5인 공부 시간을 알아내면
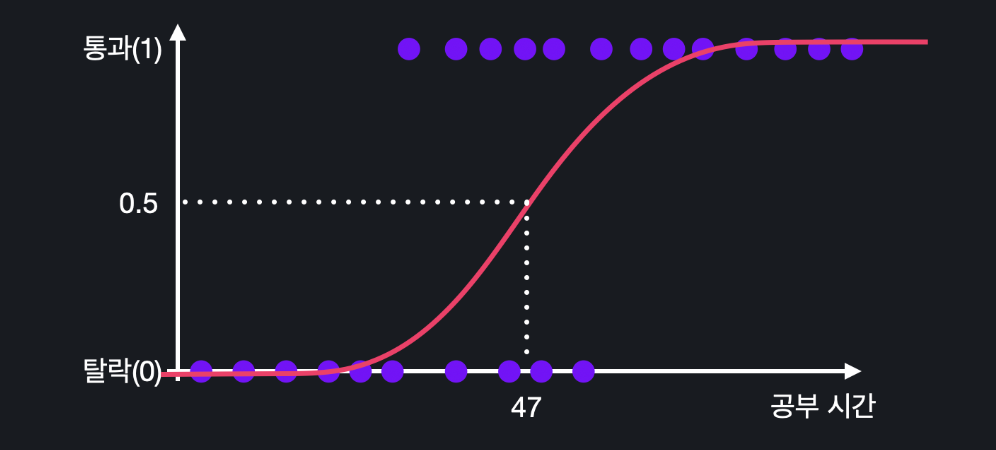
47 시간 이상 공부한 모든 학생은 통과, 47시간 미만 공부한 모든 학생은 탈락, 이렇게 예측할 수 있습니다.

이렇게 47시간에 선을 긋고 모든 데이터에 대해서 파란색 영역에 있으면 통과, 빨간색 영역에 있으면 탈락이라고 할 수 있습니다. 이렇게 분류를 할 때, 분류를 구별하는 경계선을 결정 경계 (Decision Boundary)라고 부릅니다.
2. 속성이 2개일 때
속성이 2개일 때 로지스틱 회귀 가설 함수를 시각화 하는건 어려운데 Decision Boundary를 시각화하는 건 쉽습니다. 이번에는 공부 시간, 모의고사 시험 점수를 가지고 시험을 통과했는지를 예측한다고 해봅시다. 공부시간을 x1, 모의고사 시험 점수를 x2라고 했을 때 아래와 같은 가설함수를 만들 수 있습니다.
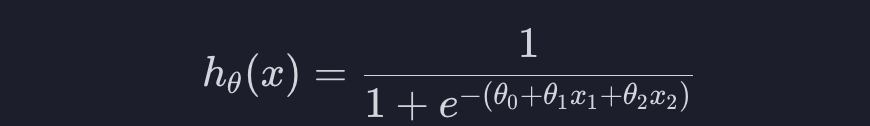
이 함수의 결과가 0.5 이상이면 시험을 통과, 미만이면 탈락을 예측할 수 있습니다. 변수가 하나일 때 47시간에 선을 그릴 수 있던 것처럼, 이 내용을 시각화하면 아래와 같은 선을 그릴 수 있습니다.
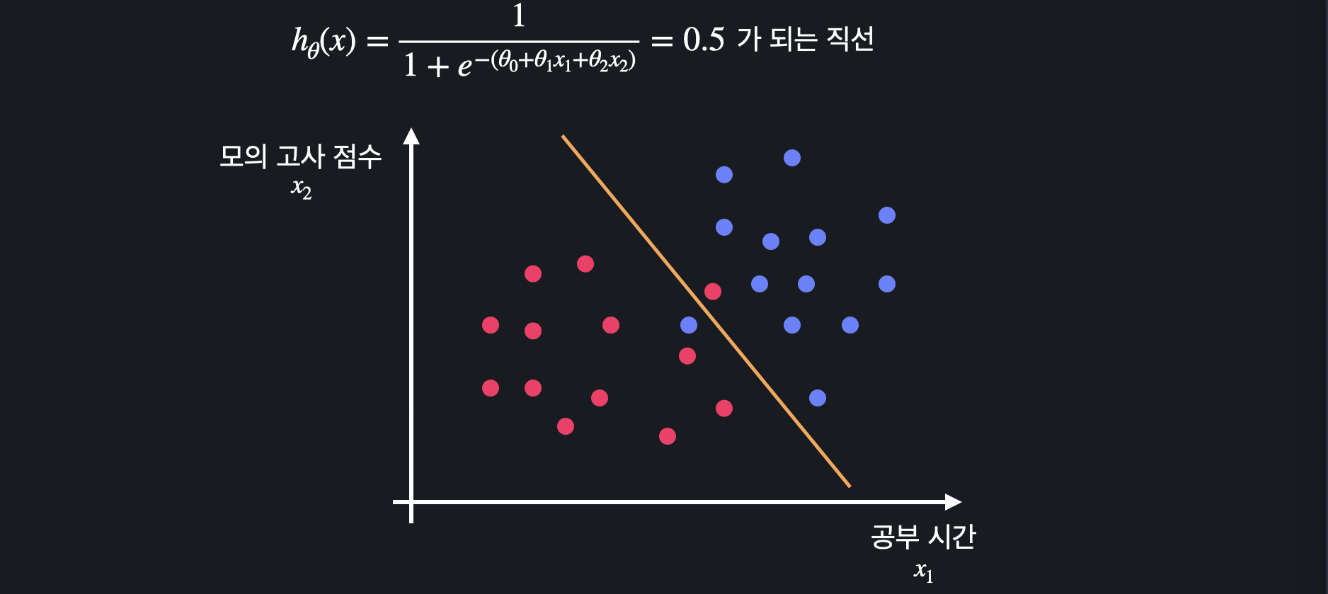
위 식을 풀면 변수 x1과 x2의 관계식을 구할 수 있습니다. 예를 들어 x2=-2x1+100 이 함수가 데이터를 분류하는 기준선(주황색 선)이 됩니다.
이 선 위에 있는 데이터는 통과 예측, 밑에 있는 데이터는 탈락을 예측할 수 있습니다.
이때 Decision Boundary를 시각화하면 아래와 같습니다.
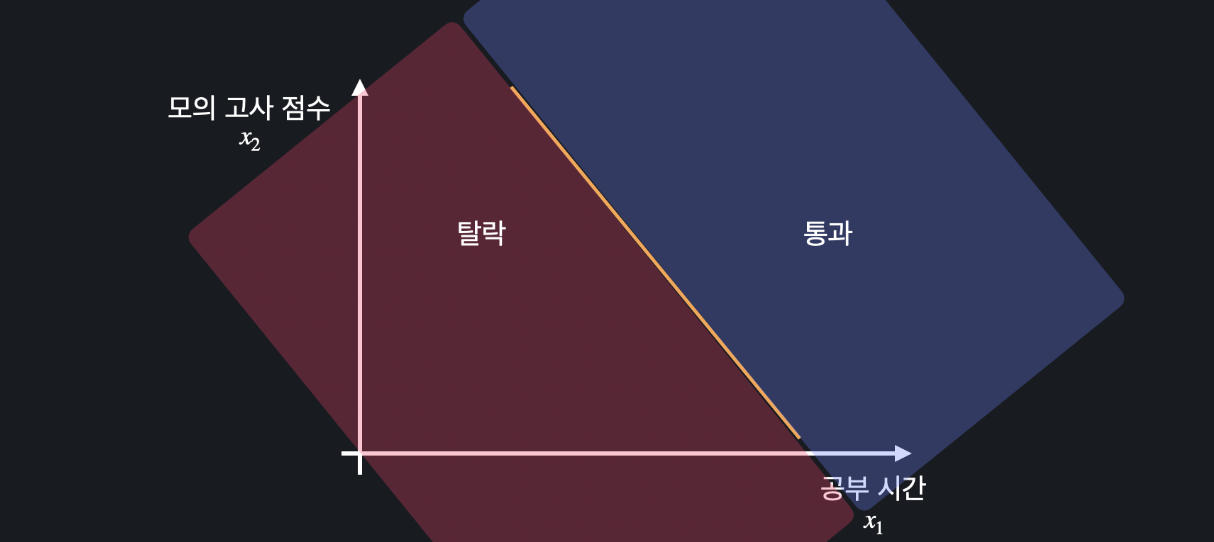
Decision Boundary는 말 그대로 데이터를 분류하는 결정 경계선을 의미합니다. 로지스틱 회귀 뿐만 아니라 분류를 하는 모든 문제들에 적용할 수 있는 개념입니다. Decision Boundary도 다른 개념들과 비슷하게 변수가 많아질수록 시각적으로 표현하기 힘들어집니다. 하지만 시각적으로 데이터를 나누는 경계선 또는 영역을 그리고 싶을 때 사용하면 됩니다.
'Coding > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 로지스틱 회귀 경사 하강법 (0) | 2023.09.13 |
|---|---|
| (Machine Learning) 로지스틱 회귀 로그 손실, 손실 함수 (0) | 2023.09.13 |
| (Machine Learning) 로지스틱 회귀 (0) | 2023.09.12 |
| (Machine Learning) 분류 (0) | 2023.09.12 |
| (Machine Learning) 다중 다항 회귀 (0) | 2023.09.08 |



