
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 코딩독학
- sql연습문제
- Seaborn
- 코드잇 TIL
- 머신러닝
- numpy
- matplotlib
- 윈도우함수
- 경사하강법
- CSS
- 영국석사
- 런던
- SQL
- 결정트리
- 파이썬
- 오늘도코드잇
- for반복문
- 로지스틱회귀
- 나혼자코딩
- 선형회귀
- 다항회귀
- 코딩공부
- 판다스
- 코드잇TIL
- 코드잇
- 유학생
- 코딩
- HTML
- 데이터분석
- 행렬
Archives
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(데이터분석) 파이썬으로 timeseries 시계열 데이터 정제하기 본문
728x90
반응형
파이썬의 datetime 이용해서 time series(시계열) 데이터를 정제해보겠습니다.
time series는 시간에 따른 데이터를 저장할 때 자주 사용되는 데이터 형식입니다.
이는 일정한 시간 간격으로 수집한 일련의 데이터 포인트들로써 시간에 따른 추세, 패턴을 분석하거나 예측하는 데 사용됩니다.
이 글에서는 pandas에서 날짜 데이터를 처리하고 시계열 데이터를 정제하는 방법을 알아보겠습니다.
time series(시계열) datetime 모듈에 대한 참고자료는 아래와 같습니다.
(파이썬 코딩일기) datetime 모듈
import datetime스탠다드 라이브러리에 있는 datetime 모듈은 '날짜'와 '시간'을 다루기 위한 다양한 '클래스'를 갖추고 있습니다. 1. datetime 값 생성2020년 3월 14일을 파이썬으로 어떻게 표현할 수 있을
life-of-nomad.tistory.com
- 먼저, pandas와 numpy 패키지를 불러오겠습니다.
import pandas as pd
import numpy as np- 이 글에서 사용할 데이터는 두 개의 열로 구성된 가상의 주가 데이터 테이블입니다.
- 첫 번째 열은 2018년 1월 1일부터 2021년 3월 1일까지의 모든 날짜로 구성되어 있습니다.
- 날짜는 연도, 월, 일 순의 형식으로 입력되어 있습니다.
- 두 번째 열인 volumne (in millions)는 백만 단위로 표시한 각 거래일의 주식 거래량입니다.
#date is in YYYY-MM-DD (%Y-%m-%d) format
df = pd.read_csv('time_series_data.csv')
df.head()
1. Inspect the data 데이터 탐색
- .describe 메서드의 결과를 보면 volume열은 10부터 600까지의 값으로 구성되어 있습니다.
df.describe()
- .info 메서드를 사용해 보면 Date열의 데이터 유형은 object 입니다. 날짜 정보가 문자열로 입력되어 있다는 뜻입니다.
- volume 열의 데이터 유형은 숫자 데이터 형식인 int64 입니다.
df.info()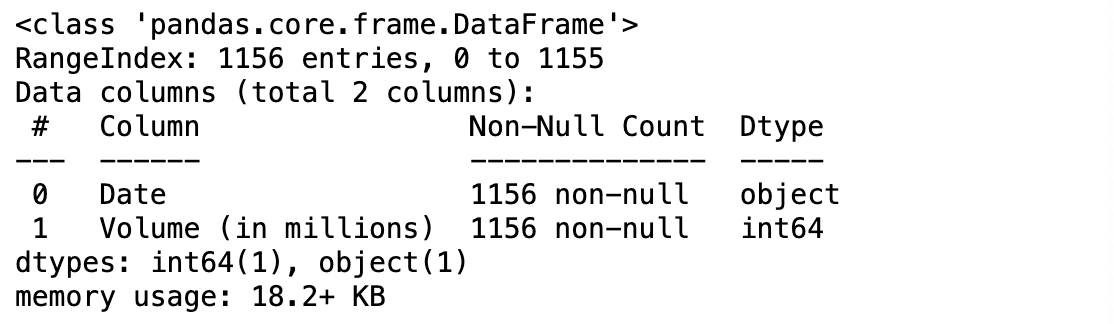
- 주어진 DaraFrame에 대해 df.plot을 실행하고 date를 x축에, volume을 y축에 나타내면 시계열 데이터를 시각화할 수 있습니다.
df.plot(x='Date', y='Volume (in millions)')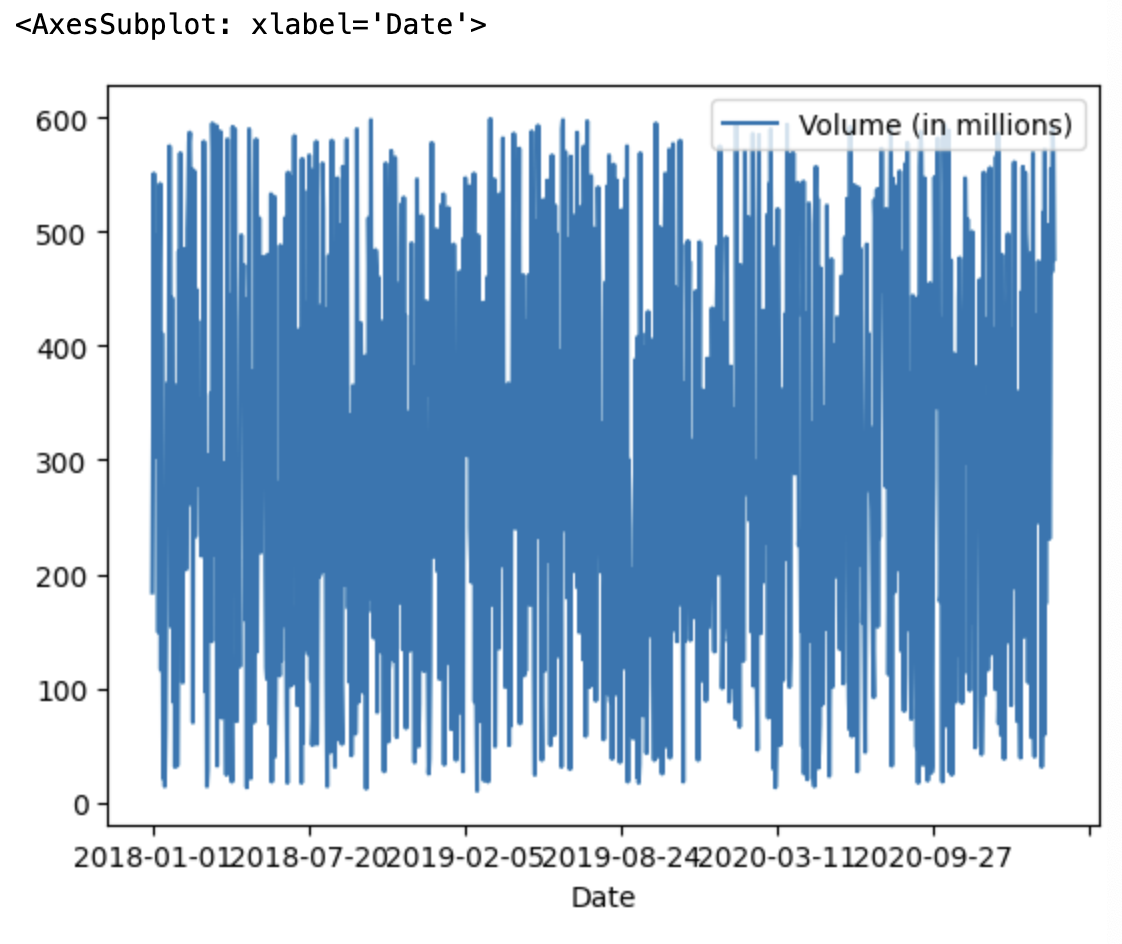
2. Convert "Date" column to datetime objects
- 이제 데이터 랭글링 작업을 해봅시다.
- 가장 먼저 해야할 작업은 Date 열의 유형을 object 에서 pandas datetime으로 바꾸는 것입니다.
- 그러기 위해서는 Date 열에 대해 to_datetime 메서드를 사용하면 됩니다.
df['Date'] = pd.to_datetime(df['Date'])- .info 로 확인해보면 date의 데이터 유형이 datetime64[ns]로 바뀌었습니다.
- ns는 나노초 기반 시간 형식을 의미하며 datetime 객체의 정밀도를 나타냅니다.
df.info()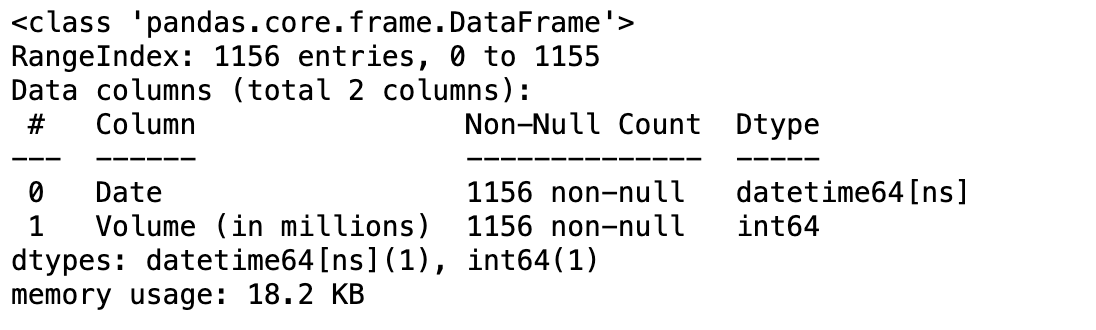
- 이 데이터세트가 다루는 시간의 범위를 확인하고 싶다면 date열에 대해 max와 min 함수를 사용해서 그 범위가 1,155일 이라는 것을 확인할 수 있습니다.
df['Date'].max() - df['Date'].min()
- 만약 연도 열이 존재하는 다른 데이터 테이블과의 병합 등을 위해서 Date열에서 연도 정보를 추출하고 싶다면 dt접근자를 이용해 dt.year이라고 표기해서 datetime 객체의 연도를 찾아낼 수 있습니다.
- 연도를 나타내는 Year열을 DataFrame에 새로 추가합니다.
df['Year'] = df['Date'].dt.yeardf.head()
3. Set "Date" column to the index
- 그 다음, date 열을 인덱스로 지정하겠습니다.
- 이 작업은 일반적으로 날짜 열을 datetime 객체로 변환한 후에 바로 수행할 수 있습니다.
- date 열을 datetime 인덱스로 변환합니다. 이는 .info 메서드와 .index 메서드의 결과에서도 확인할 수 있습니다.
df = df.set_index('Date')
df.head()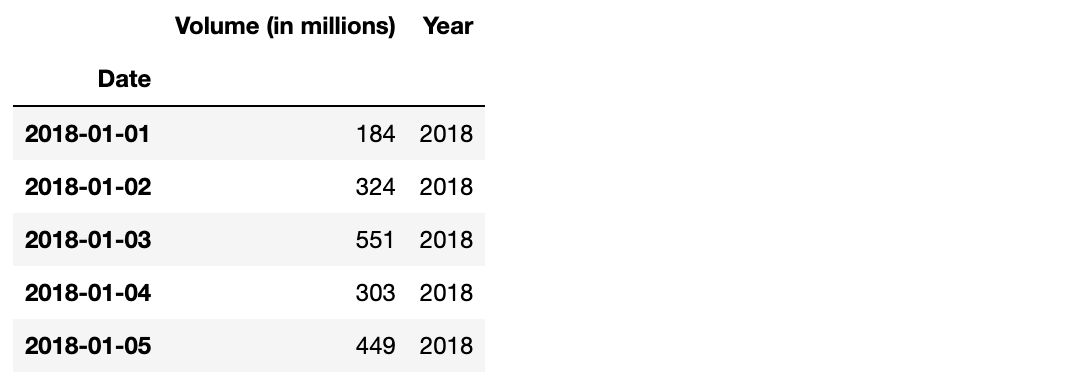
df.index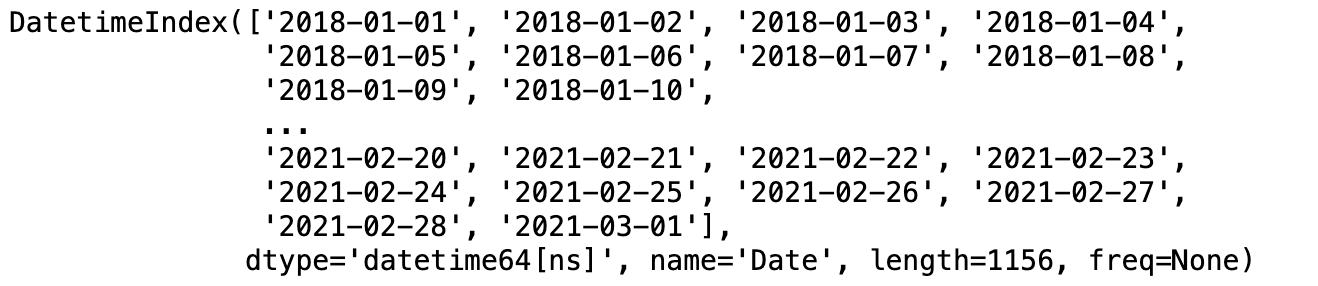
- 이제, 리샘플링 해보겠습니다.
- resampling : 시계열 데이터의 groupby 라고 할 수 있으며 시계열 데이터를 지정한 시간 간격으로 그룹화하여 추후 집계에 활용할 수 있도록 만드는 작업
- 데이터세트에서 연도별 평균 거래량을 구하고 싶다고 해봅시다.
- 먼저, df.resample("Y")를 사용합니다. Y는 연도를 의미합니다. 이는 변환할 대상을 지정하는 매개변수입니다.
- 그리고 volume에 대해 .mean을 사용해서 데이터세트의 연도별 평균 거래량을 구합니다.
df.resample("Y")['Volume (in millions)'].mean()
- 이 코드블록 끝에 .plot을 추가하기만 하면 이 결과를 차트로 나타낼 수도 있습니다.
df.resample("Y")['Volume (in millions)'].mean().plot();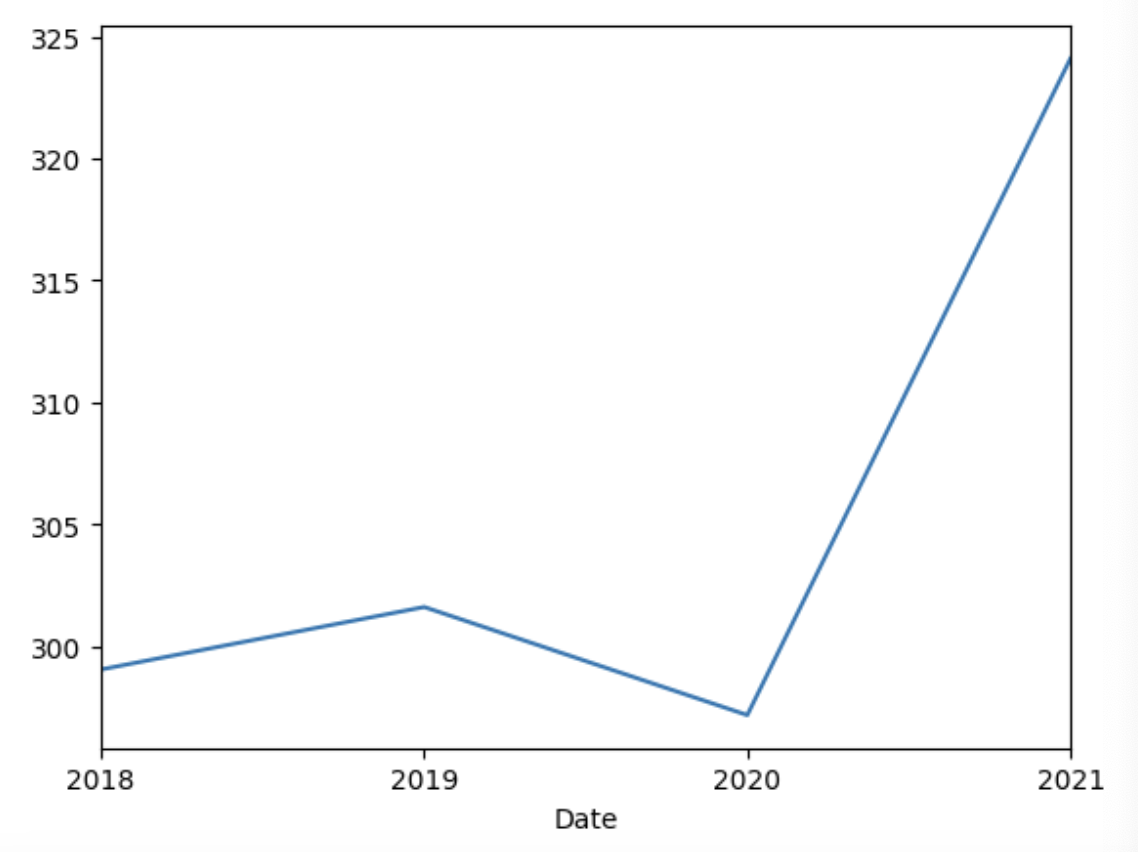
- 그 다음으로, 각 날짜의 요일을 알고 싶다고 해봅시다.
- 이 경우에는 인덱스에 대해 dayofweek를 사용하면 각 날짜의 요일을 차례대로 구할 수 있습니다.
- 월요일은 0, 화요일은 1, 일요일은 6입니다.
df['day_of_week'] = df.index.dayofweek
df.head()
- 이는 월요일에 해당하는 모든 행을 찾아내는 작업 등에 활용할 수 있습니다.
- 또한 isin 함수로 원하는 요일을 모두 찾아내고 그 평균 거래량을 구할 수도 있습니다.
mondays = df[(df['day_of_week'].isin([0]))]
mondays.head()
mondays['Volume (in millions)'].mean()
- datetime 인덱스는 다른 형태로도 만들 수 있습니다.
- Date 변수를 지정된 형식으로 변환할 수 있다는 것입니다.
- 먼저, DataFrame의 사본을 만듭니다. 이는 원본의 datetime의 인덱스를 유지하기 위함입니다.
- 그 다음, DataFrame의 인덱스에 대해 .strftime를 적용해서 아래의 형식을 지정합니다.
temp_df = df.copy()
temp_df.index = df.index.strftime('%B %d, %Y')
temp_df.head()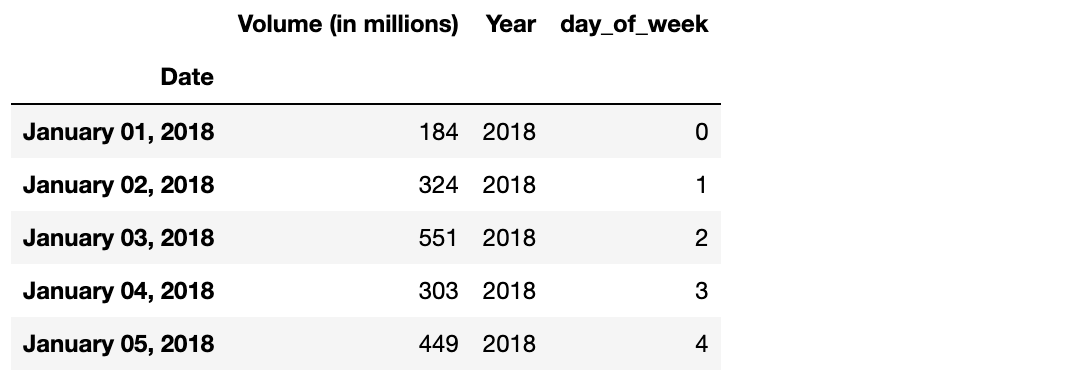
4. Dealing with missing data
- 마지막으로 시계열 데이터의 결측값을 처리하는 방법을 알아보겠습니다.
new_df = pd.read_csv('missing_time_series_data.csv', index_col = 'index')
new_df.head()
- 위에서 말했듯이, 가장 먼저 수행해야할 작업은 날짜 정보를 datetime 객체로 변환하는 것입니다.
new_df['Date'] = pd.to_datetime(new_df['Date']
new_df.head()
- .isna 메서드를 사용해보면 NA 값이 다수 존재합니다.
- .sum 으로 NA 값의 개수를 반환해보겠습니다.
new_df.isna().sum()
- .fillna 함수를 사용해서 결측값을 ffill으로 채웁니다. 이렇게 설정하면 동일한 열에서 직전의 유효한 값이 결측값을 대체합니다.
new_df = new_df.fillna(method="ffill")- 다시 확인해보면 fillna을 적용한 결과 NA가 사라진 것을 알 수 있습니다.
new_df.isna().sum()
728x90
반응형
'코딩공부 > Data analysis' 카테고리의 다른 글
| (데이터분석) seaborn과 matplotlib으로 막대그래프 작성하기 (0) | 2024.05.23 |
|---|---|
| (데이터분석) 데이터 정제 결과를 시각적 방식과 프로그래밍 방식으로 테스트하기 (0) | 2024.05.21 |
| (데이터분석) 파이썬으로 텍스트 데이터 정제하기 (0) | 2024.05.20 |
| (데이터분석) 파이썬으로 텍스트 데이터 정제 함수 만들기 (0) | 2024.05.20 |
| (데이터분석) Scikit-Learn 사이킷런으로 데이터 전처리하기 (0) | 2024.05.20 |
'코딩공부/Data analysis' Related Articles
more



