
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- 선형회귀
- 나혼자코딩
- sql연습문제
- 파이썬
- 코딩공부
- CSS
- 머신러닝
- 행렬
- 코딩
- 유학생
- 코드잇
- for반복문
- 판다스
- 코드잇TIL
- 데이터분석
- SQL
- 결정트리
- 런던
- 오늘도코드잇
- 로지스틱회귀
- 경사하강법
- 영국석사
- numpy
- 다항회귀
- Seaborn
- 코드잇 TIL
- matplotlib
- 윈도우함수
- HTML
- 코딩독학
Archives
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(데이터분석) Scikit-Learn 사이킷런으로 데이터 전처리하기 본문
728x90
반응형
사이킷런으로 할 수 있는 전처리 도구에 대해 몇 가지 알아보겠습니다.
1. Scikit-learn Pre-processing 사이킷런 불러오기
import sklearn
import numpy as mp
from sklearn.preprocessing import OneHotEncoder, StandardScaler, OrdinalEncoder
from sklearn.imput import SimpleImputer
from sklearn import set_config
#sklearn 패키지의 transform과 fit_transform 함수가 pandas DataFrame 형식으로 결과를 출력하게 하는 설정
set_config(transform_output = "pandas")
2. Scaling (데이터 표준화)
- 상당수의 데이터는 변수에 따라서 스케일 및 범위가 서로 다를 수 있습니다.
- 특히 머신 러닝 작업에서 각종 변수의 척도는 크게 다르기 때문에 이 데이터를 표준화 해서 머신러닝 훈련에 사용할 수 있는 형태로 정제할 필요가 있습니다.
- 가장 일반적인 데이터 표본 스케일링 방법은 평균을 뺀 다음 단위 분산으로 스케일링 하는 것입니다.
tiny_data = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
#sklearn의 StandardScaler를 적용하고 fit()에 tiny_data 데이터세트 입력
#.fit은 스케일링에 사용할 평균과 표준편차를 계산합니다.
scaler = StandardScaler().fit(tiny_data)
scaler
- 평균 출력하기
scaler.mean_
- 표준편차 출력하기
scaler.scale_
- 위에서 구한 평균과 표준편차를 사용해 실제로 스케일링 작업을 수행하는 transform 함수를 적용합니다.
- 한편, fit_transform 함수를 사용하면 지금까지의 과정을 한 번에 완료할 수 있습니다.
- transform 함수를 적용하고 나면 스케일링된 데이터는 평균이 0, 분산이 1을 가짐을 알 수 있습니다.
X_scaled = scaler.transform(tiny_data)X_scaled.mean()
X_scaled.std()
3. Ordinal Encoding (순서형 인코딩)
- 인코딩은 다양한 용도로 자주 사용되는 기법입니다.
- 예를 들어, 범주형 데이터를 숫자 데이터로 변환할 때 인코딩을 사용합니다.
- 순서형 인코딩(Ordinal Encoding)이란 범주형 변수를 정수 배열로 변환하는 기법입니다.
from numpy import asarray
data = asarray([['data'], ['wrangling'], ['rocks']])
print(data)
- OrdinalEncoder를 정의하고 fit_transform을 이 데이터세트에 적용합니다.
encoder = OrdinalEncoder()
encoder.fit_transform(data)
- 결과를 보면 data에는 0이, wrangling에는 2가, rocks에는 1이 할당된 것을 알 수 있습니다.
- 이런 범주형 변수를 나타낼 때는 원-핫 인코딩이라는 기법이 자주 사용됩니다.
4. One Hot Encoding
- 원 핫 인코딩은 범주형 변수를 원-핫 형식의 숫자 배열로 변환합니다.
encoder = OneHotEncoder(sparse_output=False)
encoder.fit_transform(data)- data, wrangling, rocks로 구성된 데이터세트에 대해 각 단어에 대응하는 세 개의 열이 생성되었습니다.
- 이렇게 하면 컴퓨터가 범주형 데이터와 텍스트 데이터를 쉽게 이해할 수 있습니다.

5. Imputing missing values
- 사이킷런에서 결측값을 대체하는 법을 알아보겠습니다.
- OpenML ropository에서 데이터세트를 다운로드 하는 함수인 fetch_openml을 사용해 OpenML에서 가져온 것입니다.
- 여기서 version=1 설정에 따라서 titanic은 Pandas DaraFrame형식으로 다운로드되며 그 데이터는 변수 x와 y에 저장됩니다.
- 이어서 train_test_split 함수를 사용해서 데이터를 훈련 세트와 테스트 세트로 나눕니다.
- 이는 각각 머신 러닝 모델을 훈련하고 테스트할 때 사용되는 데이터를 말합니다.
- 매개변수 stratify는 원본 데이터세트에서의 클래스 구성 비율이 훈련 세트와 테스트 세트에서도 그대로 유지되게 합니다.
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True, parser='auto')
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)X.head()
- X는 타이타닉 승객들의 정보로 구성되어 있습니다.
y_train.head()
- Series인 y는 각 승객의 생존 여부를 나타내는 정보로 구성됩니다.
- 0은 생존하지 못했음을, 1은 생존했음을 나타냅니다.
- 이 데이터세트에 포함된 각종 변수의 데이터 유형은 제각기 다릅니다.
X.info()
- X_test DataFrame의 각 열에 존재하는 결측값의 개수를 확인해 봅시다.
- isnull 함수는 결측값은 True, 결측값이 아닌 값은 False로 나타낸 불린Boolean)값의 DaraFrame을 반환합니다.
- .sum은 각 열에서 True 값의 개수를 세서 두번째 줄의 코드는 결측값이 1개 이상 존재하는 열만을 선택한 다음 결측값 개수를 기준으로 결과를 내림차순으로 정렬해서 결과를 출력해보면 서로 다른 열에 상당수의 결측값이 존재한다는 걸 알 수 있습니다.
missing = X_test.isnull().sum()
missing = missing[missing > 0].sort_values(ascending = False)missing
- sklearn 솔루션인 SimpleImputer를 사용해서 age와 body 열에 존재하는 숫자 결측값을 대체해보겠습니다.
- place holder인 missing_value는 np.nan 으로, strategy는 mean으로 설정합니다.
- 이는 결측값을 각 열의 평균으로 대체하겠다는 뜻입니다.
- age와 body열에 이를 적용해서 평균과 표준편차를 구하고 변환하는 작업을 동시에 수행하고 그 결과를 simple_imputed에 저장합니다.
simple_imp = SimpleImputer(missing_values = np.nan, strategy = 'mean')
simple_imputed = simple_imp.fit_transform(X_test[['age', 'body']])- 그 다음, 이 작업 결과를 데이터에 반영합니다.
- 원래 X_test DataFrame의 age 와 body 열에 존재하는 결측값을 평균으로 대체하겠습니다.
- 그리고 X_test DataFrame의 결측값 개수를 구할 때 동일한 코드를 다시 실행하면 age와 body열이 결과에 나타나지 않는 것을 알 수 있습니다. 해당 열의 결측값이 대체되었기 때문입니다.
X_test[['age' 'body']] = simple_imputed
missing = X_test.isnull().sum()
missing = missing[missing > 0].sort_values(ascending=False)
missing
6. Putting it all together
- 이제, sklearn pipeline으로 이 모든 작업을 한 번에 효율적으로 처리하는 방법을 알아보겠습니다.
- pipeline은 여러 가지 sklearn 작업을 하나로 결합하고 그 워크플로를 결정하는데 사용되는 유용한 도구입니다.
- 앞에서는 사용하지 않았던 훈련 세트를 사용하겠습니다.
- sklearn pipeline을 정의한 다음 결측값을 대체할 SimpleImputer와 연속적인 변수를 스케일링할 StandardScaler와 범주형 변수를 인코딩할 OneHotEncoder을 사용합니다.
- 마지막으로 머신러닝 모델인 LogisticRegression을 pipeline에 추가합니다.
- 이제 이 훈련 데이터세트에 대해 이 sklearn pipeline을 적용할 수 있습니다.
X_train.head()
from sklearn.compose import make_column_transformer
from sklearn.pipeline import make_pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.linear_model import LogisticRegression
ct = make_column_transformer((make_pipeline(SimpleImputer(),
StandardScaler()), ["age", "fare"]),
(OneHotEncoder(sparse_output=False), ["embarked", "sex", "pclass"]),
verbose_feature_names_out=False)
clf = make_pipeline(ct, LogisticREgression())
clf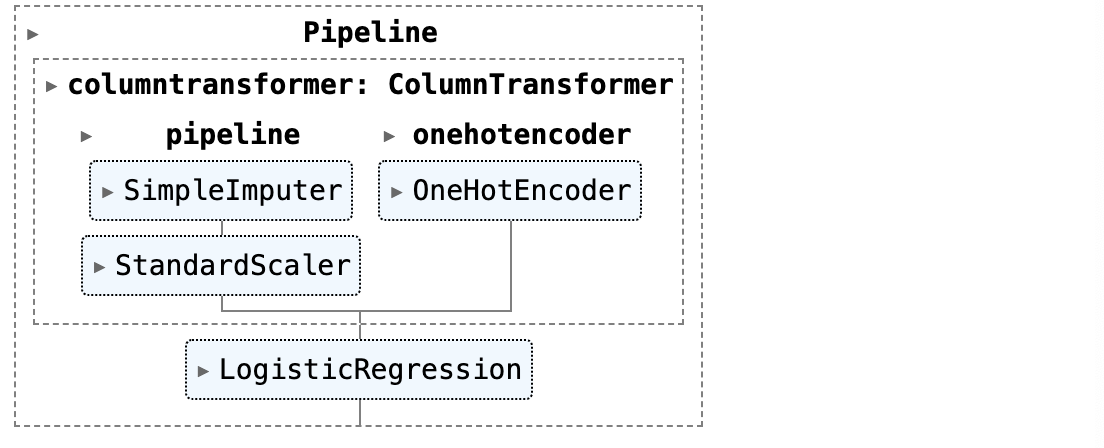
- 이제 훈련 데이터세트에 대해 이 sklearn pipeline을 적용할 수 있습니다.
- 이후에는 다양한 작업을 할 수 있습니다.
- 해당 데이터세트에 대한 모델의 성능(score)을 확인할수도 있습니다.
clf.fit(X_train, y_train)
clf.score(X_train, y_train)
- 또한 로지스틱 회귀 모델을 제거하고 테스트 데이터세트에 대한 스케일링, 인코딩, 대체 작업만 수행할 수 도 있습니다.
clf[:-1].transform(X_test)
728x90
반응형
'코딩공부 > Data analysis' 카테고리의 다른 글
| (데이터분석) 파이썬으로 텍스트 데이터 정제하기 (0) | 2024.05.20 |
|---|---|
| (데이터분석) 파이썬으로 텍스트 데이터 정제 함수 만들기 (0) | 2024.05.20 |
| (데이터분석) 파이썬으로 데이터 정제하기 (0) | 2024.05.19 |
| (데이터분석) 결측 데이터 처리하기 (0) | 2024.05.17 |
| (데이터분석) 중복된 값 제거하기 (0) | 2024.05.17 |
'코딩공부/Data analysis' Related Articles
more



