
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 오늘도코드잇
- SQL
- 코드잇TIL
- 파이썬
- 판다스
- 나혼자코딩
- 코드잇
- for반복문
- Seaborn
- 행렬
- 데이터분석
- 로지스틱회귀
- 코딩
- numpy
- 런던
- 코딩독학
- 유학생
- 윈도우함수
- 코드잇 TIL
- 영국석사
- 머신러닝
- 선형회귀
- sql연습문제
- 코딩공부
- 결정트리
- matplotlib
- CSS
- HTML
- 경사하강법
- 다항회귀
Archives
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(데이터분석) 데이터 정제 결과를 시각적 방식과 프로그래밍 방식으로 테스트하기 본문
728x90
반응형
데이터의 문제점을 해결하고 나서는 바로 시각적 방식이나 프로그래밍 방식의 평가를 통해서 정제 작업이 성공적이었다는 것을 확인해야 합니다. 즉, 평가 및 테스트의 워크플로를 효과적으로 구성해야 합니다.
* Test-Driven development(테스트 주도 개발) : 소프트웨어 개발을 완료하기 전에 지속적인 테스트를 수행하여 소프트웨어의 효과성을 검증하는 것
이 글에서는 데이터 정제 작업의 효과를 평가하는 방법을 알아보겠습니다.
1. Heatmap 이용하기
- 먼저, .head() 나 .tail()을 이용해서 데이터를 시각적으로 살펴볼 수 있습니다.
#import libraries
import pandas as pd
import numpy as np
import seaborn as sns
#Read the .json file
orig_pums = pd.read_json('2021-pums.json')
orig_pums.head()
- 또한, 시각적 자료도 만들 수 있습니다.
- 데이터 랭글링에서 가장 많이 사용되는 히트맵과 히스토그램에 대해 알아보겠습니다.
- 이 데이터에서 결측값이 제대로 처리되었는지 테스트해보겠습니다.
- 1) 먼저, DataFrame의 사본을 만들고
- 2) 0번째 행을 헤더로 설정해서 데이터를 정돈하고
- 3) WRK, SEX, SCOP를 변수로 취하고
- 4) WRK 열의 np.nan을 0으로 대체해서 데이터 완전성 문제를 해결했습니다.
#make copies of the dataframe
cleaned_pums = orig_pums.copy()
#Define the 0th row as the heather
cleaned_pums.columns = cleaned_pums.iloc[0]
cleaned_pums = cleaned_pums.drop(cleaned_pums.index[0])
cleaned_pums = cleaned_pums.reset_index(drop=True)
#keep the WRK, SEX, and SCOP variables
cleaned_pums = cleaned_pums[['WRK', 'SEX', 'SOCP']]
#replace 0 values in WRK column with np.nan
cleaned_pums['WRK'] = cleaned_pums['WRK'].replace({'0':np.nan})- 이제 이 데이터에 존재하는 결측값을 시각화해보겠습니다.
- seaborn 라이브러리를 사용해서 히트맵을 만들겠습니다.
sns.heatmap(cleaned_pums.isna().transpose(), cbar_kws={'lable':'Missing Data'})
- 이 차트는 PUMS 데이터세트의 일부 변수에 존재하는 결측값의 패턴을 시각적으로 나타내고 있습니다.
- 직업코드를 나타내는 SOCP, 성별 SEX, 개인별 지난주의 근로 여부를 나타내는 WRK 변수에 대해 나타내고 있습니다.
- 이 히트맵을 작성하기 위해 .isna 메서드를 사용하고 그 결과를 transposing 해서 seaborn heatmap 함수에 전달했으며 측면에는 missing data 라는 레이블을 표기했습니다.
- 이 히트맵에서 흰색의 수직선은 각 변수에 존재하는 결측값을 나타냅니다.
- WRK 열에는 여러 개의 결측값이 존재한다는 것을 알 수 있습니다.
- 이제, 이 변수에 대해 .dropna함수를 사용해서 NA 값을 제거해봅시다.
cleaned_pums = cleaned_pums.dropna()- 이 히트맵을 다시 그리면 흰 선은 보이지 않으며, 색상을 통해 결측값이 없다는 걸 알 수 있습니다.
2. histogram 이용하기
- 데이터를 시각화하는 또 다른 방법은 데이터 값의 분포를 나타내는 히스토그램을 작성하는 것입니다.
- OEWS의 데이터세트를 업로드해서 정제해보겠습니다.
orig_wage_df = pd.read_excel('oes_research_2021_sec_55-56.xlsx')
orig_wage_df.head()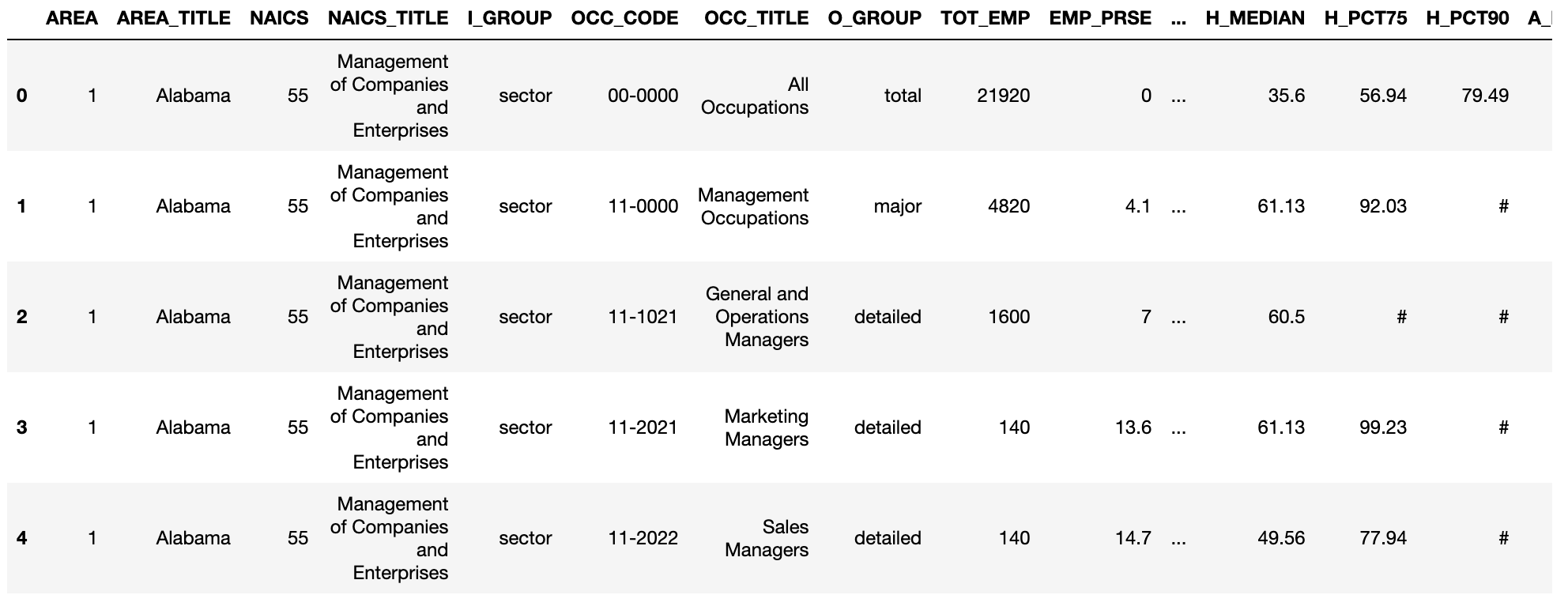
- DataFrame의 사본을 만들고 *과 #을 NA로 교체하고 DataFrame을 필터링해 특정 변수만 남긴 다음 다시 필터링을 통해 California에 해당하는 값만 남깁니다.
- 마지막으로는 NA 값을 제거합니다.
#Make copies of the dataframes
cleaned_wage = orig_wage_df.copy()
#Replace alphanumeric characters (missing values + outliers) with NANs
cleaned_wage['H_MEAN'] = cleaned_wage['H_MEAN'].replace({'*':np.nan})
cleaned_wage['H_MEAN'] = cleaned_wage['H_MEAN'].replace({'#':np.nan})
#Filtering the dataframe to specific data elements
cleaned_wage = cleaned_wage[['AREA_TITLE', 'OCC_CODE', 'OCC_TITLE', 'H_MEAN']]
#Filter to only contains values pertaining to California
cleaned_wage = cleaned_wage[cleaned_wage['AREA_TITLE'] == 'California']
#Drop NA values
cleaned_wage = cleaned_wage.dropna()- 이제 숫자 변수를 차트로 나타내보겠습니다.
- H_MEAN은 cleaned_wage DataFrame에서의 시간당 평균 임금을 나타내는 변수입니다.
cleaned_wage['H_MEAN'].plot.hist(bins=12, alpha=0.5);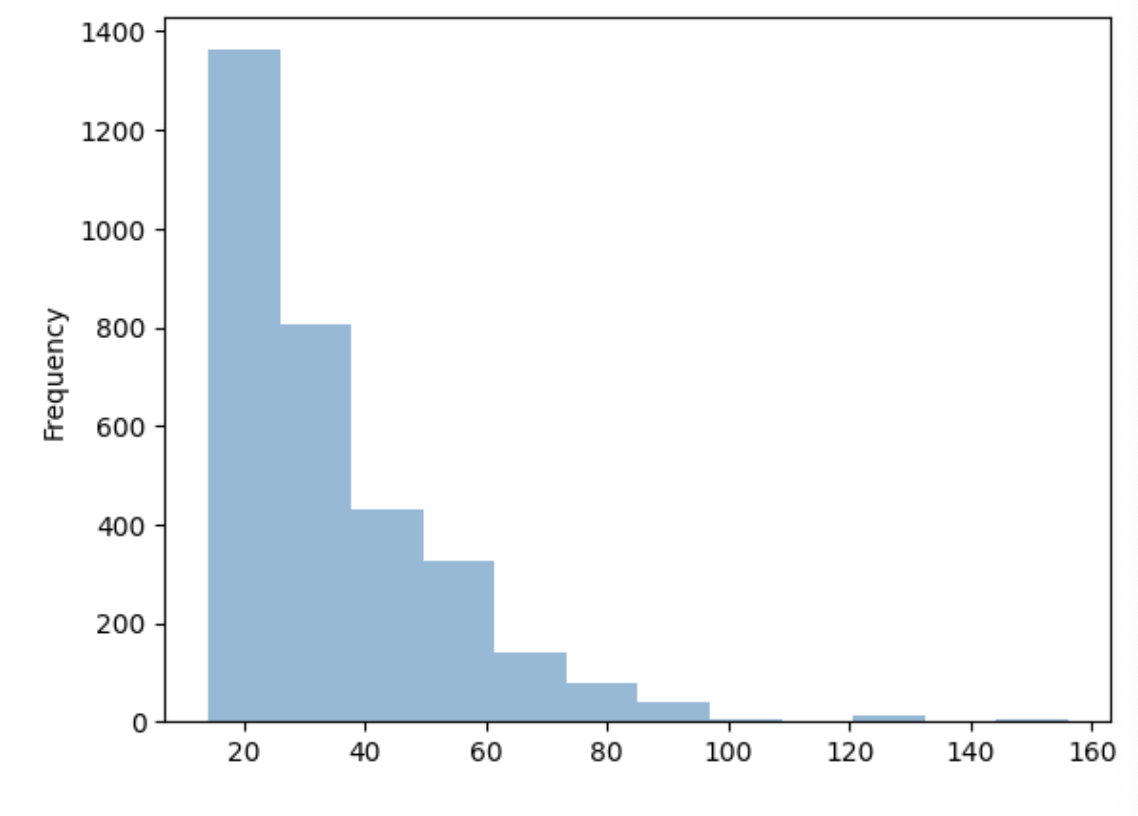
- plot.hist 함수를 사용해서 히스토그램의 계급 개수를 12개로 지정하고 투명도를 0.5로 설정했습니다.
- 참고로, plot.hist 함수는 matplotlib 라이브러리에 존재합니다.
- 이 시각화 자료를 보면 이 변수의 범위를 금방 확인할 수 있습니다.
- 대략 10달러에서 160달러 사이라는 것을 한눈에 알 수 있습니다.
- 또한, 이상치가 존재하는 것을 알 수 있고 데이터에 타당성 및 정확성 문제가 존재하는 지를 확인할 수 있습니다.
3. Programatic Asserts
- 이제 프로그래밍 방식으로 데이터를 테스트해보겠습니다.
print(cleaned_pums.info())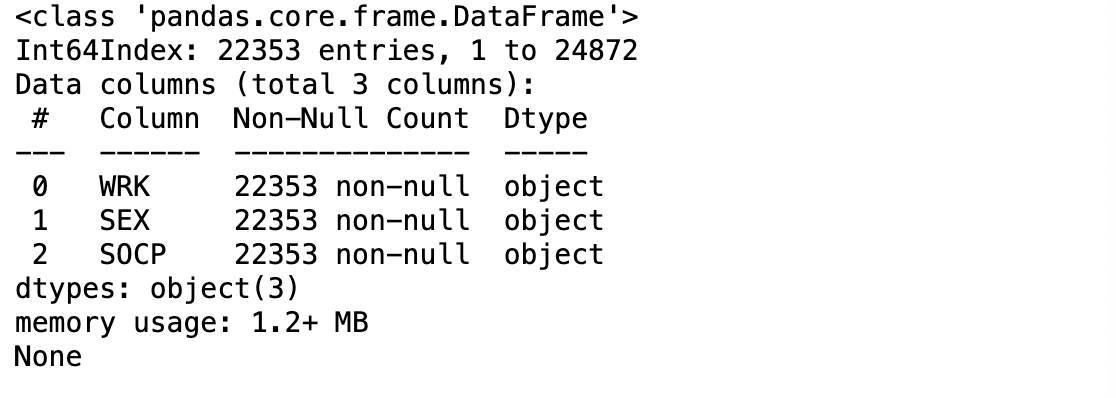
- 파이썬의 assert 문을 사용해서 데이터세트에 대한 특정 조건의 충족 여부를 확인할 수 있습니다.
- 각 열의 데이터 유형이 정확한지 확인해볼 수 있습니다.
- 이 경우 데이터세트의 모든 변수가 object가 되어야 한다고 가정해봅시다.
- 이를 확인하기 위해서는 assert문을 입력하고 dtype 메서드로 각 열의 데이터 유형을 확인한 다음 이들을 모두 object지정하면 됩니다.
assert cleaned_pums.WRK.dtype == 'object'
assert cleaned_pums.SEX.dtype == 'object'
assert cleaned_pums.SOCP.dtype == 'object'- H_MEAN의 데이터 유형이 float인지 확인할 수 있습니다.
assert cleaned_wage.H_MEAN.dtype == 'float'- 또한, 두 데이터세트에 존재하는 NA값의 개수가 모두 0이라는 것도 확인할 수 있습니다.
assert cleaned_pums.isnull().sum().sum() == 0assert cleaned_wage.isnull().sum().sum() == 0- 만약, 정제 작업이 잘못되어 assert문에서 지정한 조건이 충족되지 않는다면 오류를 발생시키게 됩니다.
assert (cleaned_wage.H_MEAN <= 150).all()
728x90
반응형
'코딩공부 > Data analysis' 카테고리의 다른 글
| (데이터분석) seaborn의 절대도수와 상대도수 막대그래프 나타내기 (0) | 2024.05.24 |
|---|---|
| (데이터분석) seaborn과 matplotlib으로 막대그래프 작성하기 (0) | 2024.05.23 |
| (데이터분석) 파이썬으로 timeseries 시계열 데이터 정제하기 (0) | 2024.05.21 |
| (데이터분석) 파이썬으로 텍스트 데이터 정제하기 (0) | 2024.05.20 |
| (데이터분석) 파이썬으로 텍스트 데이터 정제 함수 만들기 (0) | 2024.05.20 |
'코딩공부/Data analysis' Related Articles
more



