
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- SQL
- 런던
- 결정트리
- matplotlib
- HTML
- 유학생
- CSS
- 판다스
- 코드잇TIL
- 나혼자코딩
- 코드잇
- numpy
- 선형회귀
- 코딩
- for반복문
- Seaborn
- 코딩공부
- 머신러닝
- 영국석사
- 데이터분석
- 경사하강법
- 코드잇 TIL
- sql연습문제
- 다항회귀
- 코딩독학
- 행렬
- 오늘도코드잇
- 로지스틱회귀
- 윈도우함수
- 파이썬
Archives
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(데이터분석) 파이썬의 zipfile 이용하여 플랫파일 압축 해제하고 읽기 본문
728x90
반응형
zipfile 이용하기
- zipfile.ZipFile을 통해 ZipFile 클래스에 엑세스해서 zipfile 라이브러리로부터 zip파일을 읽고 쓸 수 있게 합니다.
- "r"을 지정하여 tiny_csv_zip이라는 이름의 zip파일을 읽기모드에서 열고 zip_ref라는 파일 객체를 생성합니다.
- extractall 함수를 사용해서 zip파일 내의 모든 파일을 tiny_csv라는 이름의 새 폴더로 추출합니다.
- pandas 이용해서 tiny_csv폴더에서 csv파일을 읽어서 DataFrame 으로 반환합니다.
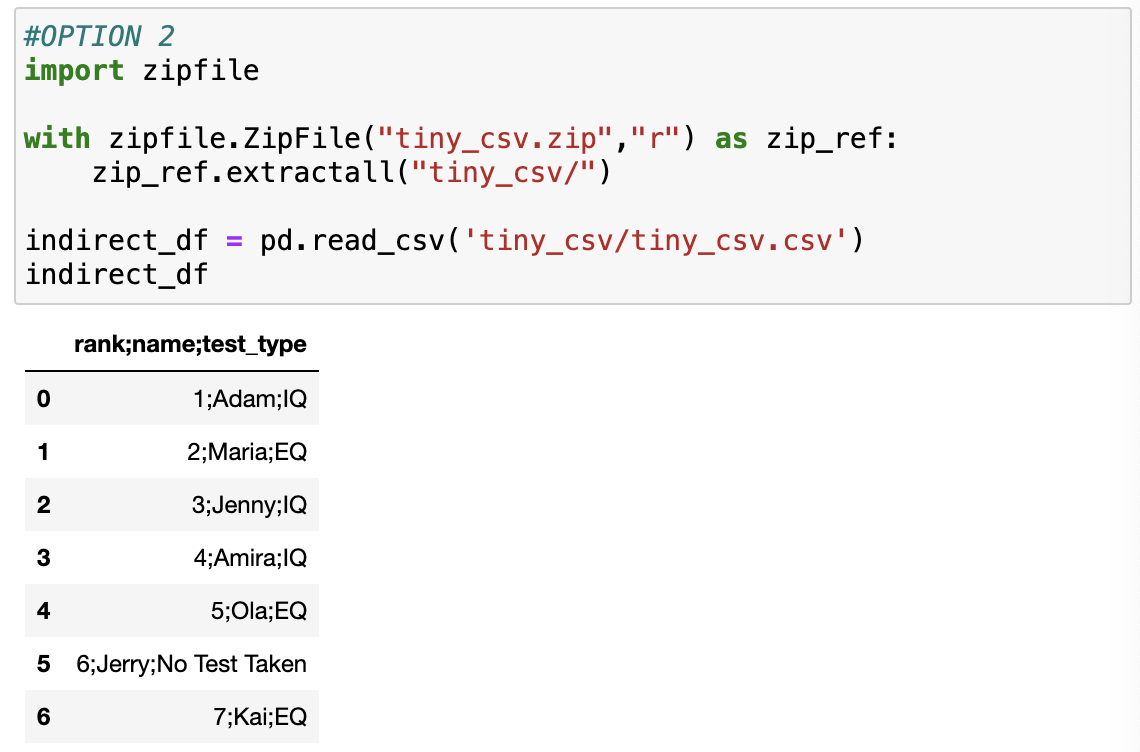
- 문제점
- pandas가 세미콜론(;)을 제대로 처리하지 못합니다. (pandas는 기본적으로 쉼표로 값을 구분하기 때문)
- 테스트 결과가 없는 것이 존재합니다. No Test Taken => 누락값은 NA로 나타내는게 적합합니다.
- rank열에도 각 참가자에게 부여된 고유의 값이 입력되어 있습니다. => 두 개의 다른 인덱스를 사용해야 함
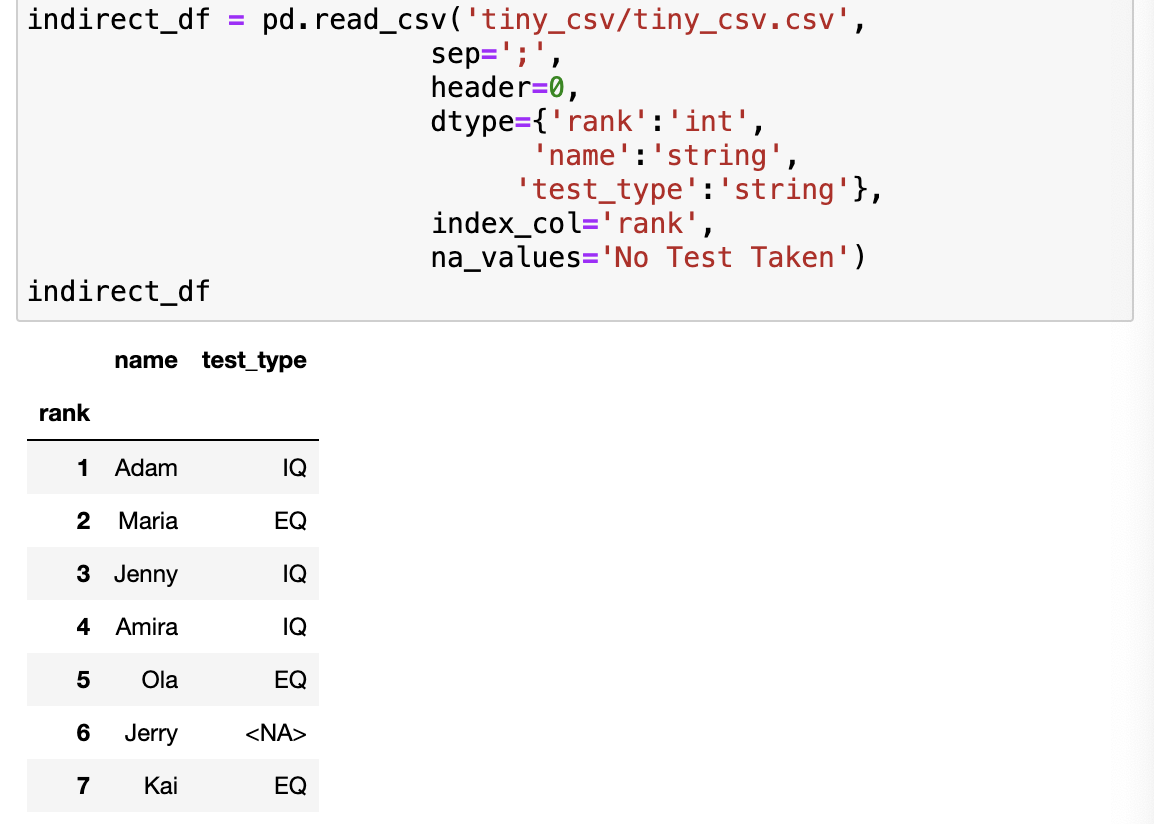
- 코드를 다시 추가해봅시다.
- sep : 세미콜론을 구분 기호로 정의합니다.
- header : 헤더를 csv파일의 첫 번째 행으로 정의합니다.
- dtype : 각 열의 데이터 유형을 지정합니다. (rank는 정수, name과 test_type은 문자열)
- index_col : rank를 index변수로 사용하도록 지정하여 인덱스가 중복되지 않게 합니다.
- no_values : No Test Taken 을 결측값으로 지정합니다.
728x90
반응형
'코딩공부 > Data analysis' 카테고리의 다른 글
| (데이터분석) 파이썬의 glob 라이브러리 사용하여 텍스트파일 읽기 (0) | 2024.05.10 |
|---|---|
| (데이터분석) 파이썬의 requests 라이브러리 이용하여 파일 다운로드하기 (0) | 2024.05.10 |
| (데이터분석) Q1, Q3, 이상값 (1) | 2023.06.17 |
| (데이터분석) pandas DataFrame 인덱싱 문법 정리 (0) | 2023.06.06 |
| (데이터분석) pandas의 데이터 타입 (0) | 2023.06.01 |
'코딩공부/Data analysis' Related Articles
more



