
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- Seaborn
- CSS
- 코딩공부
- 머신러닝
- 코드잇
- SQL
- 나혼자코딩
- 선형회귀
- matplotlib
- 코드잇TIL
- 코딩
- sql연습문제
- 경사하강법
- 윈도우함수
- for반복문
- 유학생
- 파이썬
- 데이터분석
- 판다스
- 코드잇 TIL
- numpy
- 코딩독학
- 다항회귀
- 로지스틱회귀
- 런던
- 결정트리
- HTML
- 행렬
- 오늘도코드잇
- 영국석사
Archives
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(데이터분석) 결측 데이터 처리하기 본문
728x90
반응형
import pandas as pd
import numpy as np
#read dataframe
df = pd.read_csv('assessment.csv')
#Drop a rows
df.head()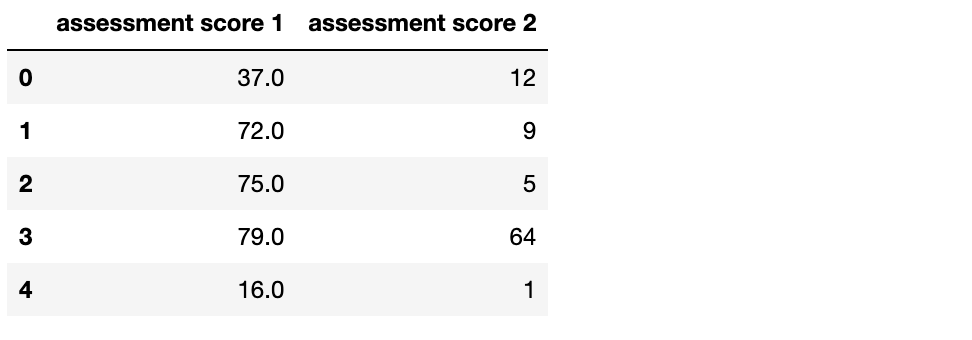
df.describe()
df.info()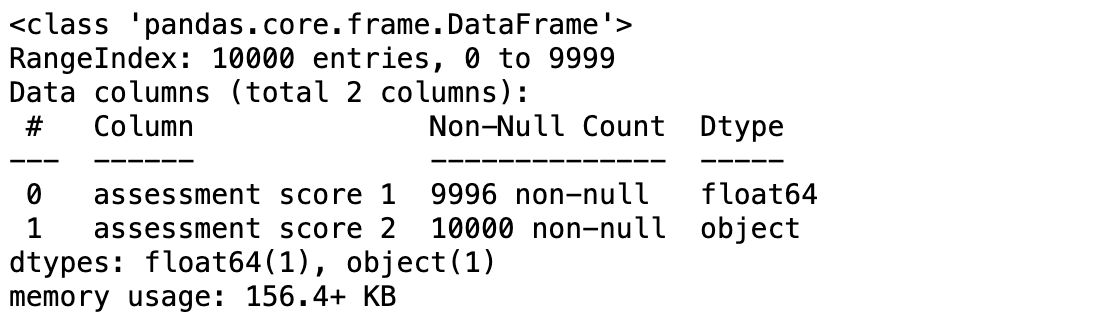
df.sample(5, random_state = 70)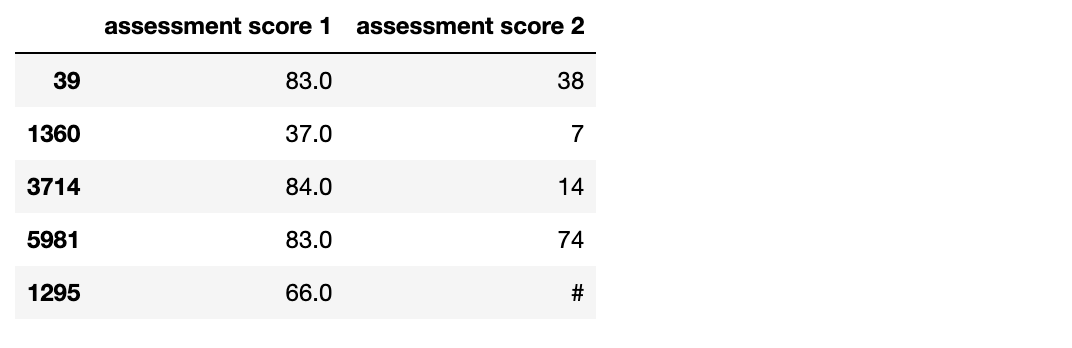
df.loc[df['assessment score 2'].isin(['#'])]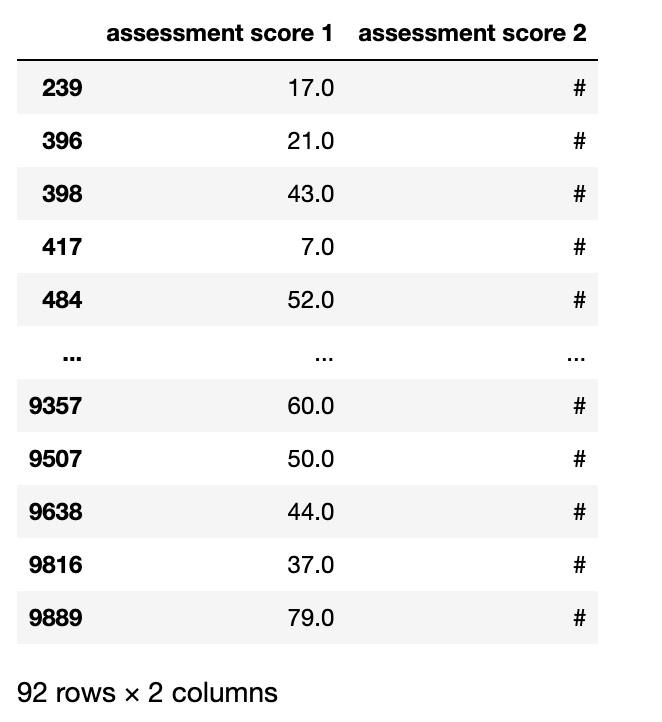
df['assessment score 2'] = df['assessment score 2'].replace({'#':np.nan})
df
df.loc[df['assessment score 2'].isin(['#'])]
df.isna().sum()
Option 1 : drop rows
cleaned_df = df.dropna()
cleaned_df.describe()
cleaned_df.isna().sum()
Option 2 : drop columns
problem_df = pd.read_csv("assessment_problem.csv")
problem_df.head()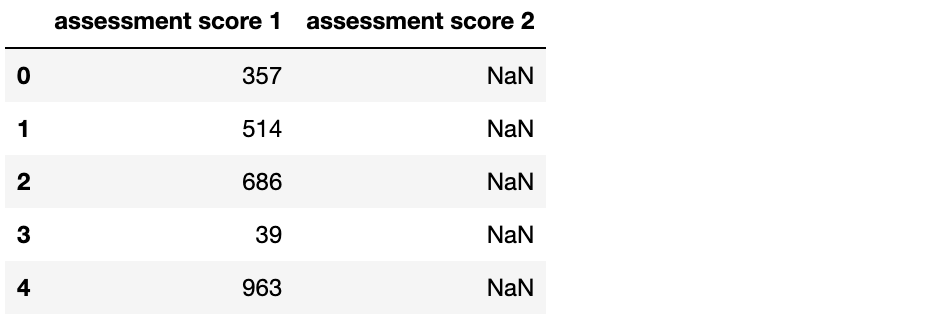
problem_df.isna().sum()
problem_df_cleaned = problem_df.drop('assessment score 2', axis=1)
problem_df_cleaned.head()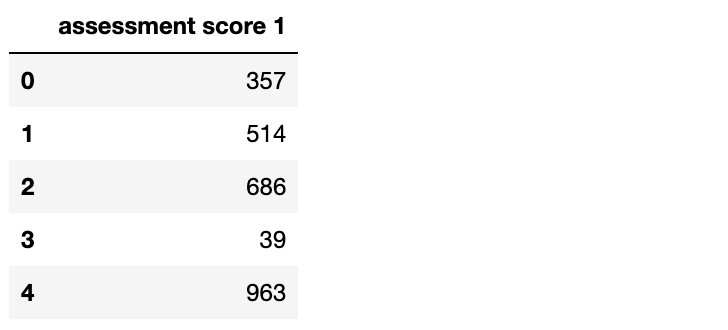
problem_df_cleaned.isna().sum()
Option 3 : impute NaNs
df = pd.read_csv('assessment.csv')
#replace '#' to nan
df['assessment score 2'] = df['assessment score2'].replace({'#':np.nan})
#convert 'assessment score 2' data type from object to float
df['assessment score 2'] = df['assessment score 2'].astype(float)df.isna().sum()
cleaned_df = df.fillna(df.mean())cleaned_df.isna().sum()
t_df = df.copy()
t_df['assessment score 2'] = t_df['assessment score 2'].fillna(
t_df['assessment score 2'].mean())t_df.isna().sum()
#A quick check on the states after imputing the data
cleand_df.describe()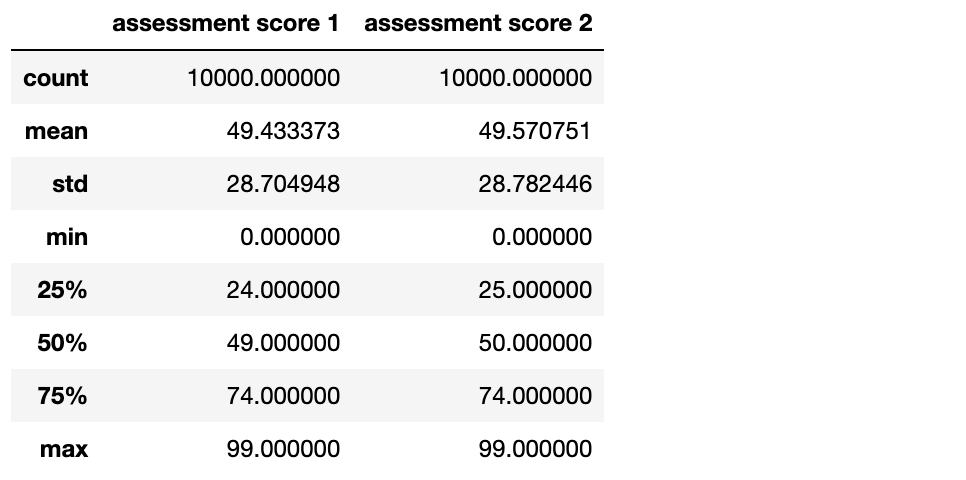
df.describe()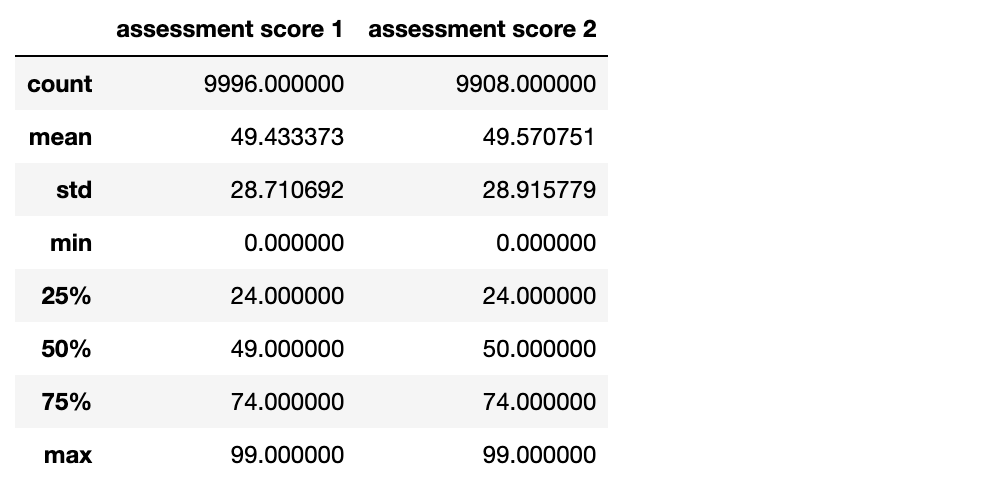
Option 4 : create bins
df['assessment score 1'] = pd.cut(df['assessment score 1'], 4)
df['assessment score 2'] = pd.cut(df['assessment score 2'], 4)df['assessment score 2'].value_counts()
df[df.isnull().any(axis=1)]
728x90
반응형
'코딩공부 > Data analysis' 카테고리의 다른 글
| (데이터분석) Scikit-Learn 사이킷런으로 데이터 전처리하기 (0) | 2024.05.20 |
|---|---|
| (데이터분석) 파이썬으로 데이터 정제하기 (0) | 2024.05.19 |
| (데이터분석) 중복된 값 제거하기 (0) | 2024.05.17 |
| (데이터분석) 웹 페이지 스크래핑 연습문제 (0) | 2024.05.13 |
| (데이터분석) 파이썬 BeautifulSoup으로 웹 페이지 스크래핑하기 (0) | 2024.05.13 |
'코딩공부/Data analysis' Related Articles
more



