
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 코딩공부
- 코드잇 TIL
- 데이터분석
- sql연습문제
- 로지스틱회귀
- 코드잇
- 행렬
- 경사하강법
- 윈도우함수
- 코드잇TIL
- 파이썬
- numpy
- 코딩
- CSS
- for반복문
- 오늘도코드잇
- matplotlib
- 다항회귀
- 결정트리
- HTML
- 런던
- 코딩독학
- Seaborn
- 판다스
- 유학생
- 선형회귀
- SQL
- 나혼자코딩
- 머신러닝
- 영국석사
Archives
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(데이터분석) 파이썬 BeautifulSoup으로 웹 페이지 스크래핑하기 본문
728x90
반응형
웹사이트에서 데이터에 액세스하기 어려울때, 코드를 사용하는 웹 스크래핑을 통해서 데이터를 추출해보겠습니다. 웹사이트 데이터는 태그를 사용해 페이지의 구조를 지정하는 하이퍼텍스트 마크업 언어(HyperText Markup Language, HTML)로 작성됩니다. 구문 분석기를 사용하여 액세스할 수 있습니다. BeautifulSoup를 사용하면 더욱 편리합니다.
* BeautifulSoup : 파이썬 언어로 작성된 HTML 구문 분석기
1) BeautifulSoup 라이브러리 불러오기

2) language_of_flowers.html 을 fp라는 파일 객체로 열기
3) Beautiful 생성자에 전달하고 그 결과를 flower_soup 변수에 할당하기

4) flower_soup 결과 확인하기
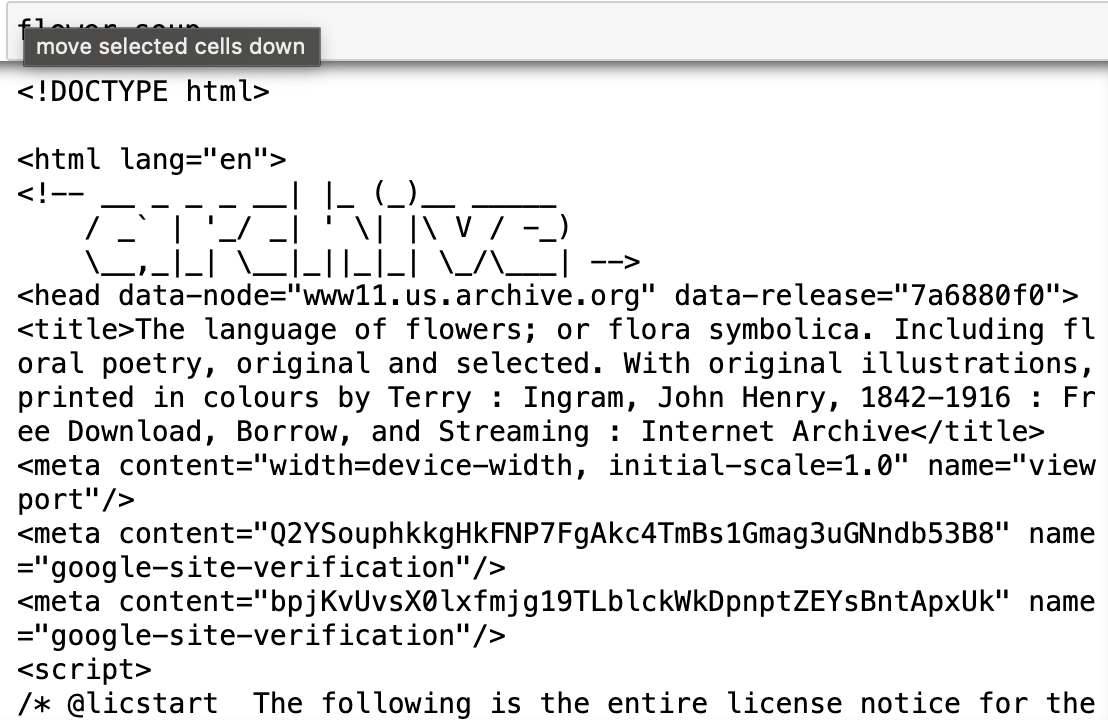
5) prettify 메서드 사용해서 줄바꿈해서 깔끔하게 정리
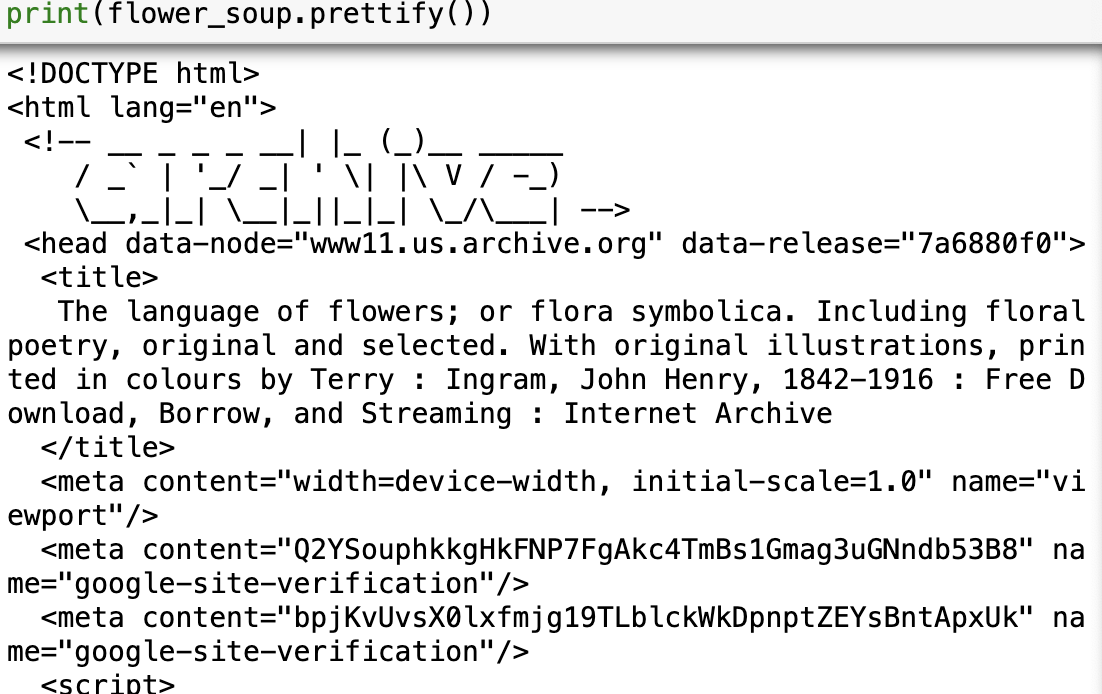
6) find 메서드 사용해서 title 추출하기
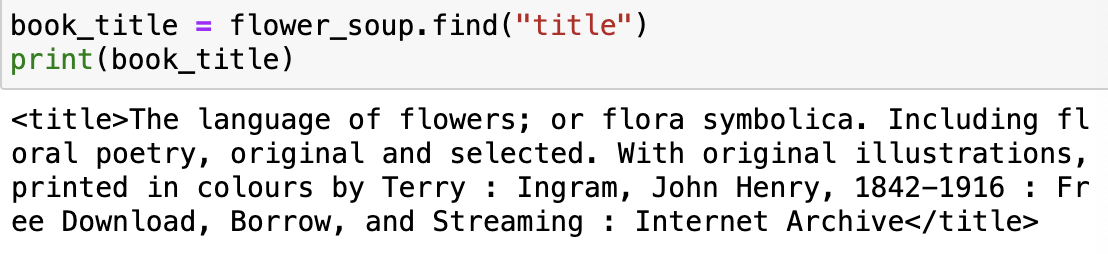
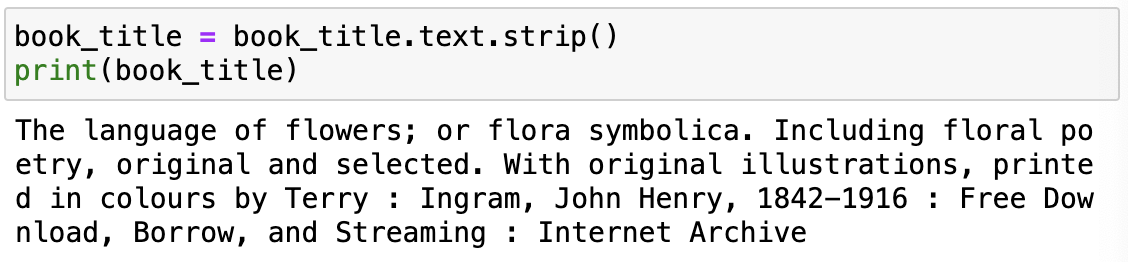
7) 태그 빼고 내용만 확인하기
- 앞의 결과에 대해.text를 사용한 다음
- .strip()으로 텍스트 전후의 공백 지우기
8) 업로드한 사람의 사용자 이름 확인하기
- find 함수 이용해 태그 유형 a로 설정하기
- 태그 클래스 class = item-upload-info_uploader-name으로 지정하기
- 출력된 결과에 .text 적용하기
- 사용자명 hank_b 반환됨

9) 한 번에 여러개 항목 찾기
- 클래스가 collection-item 인 a 태그 사이의 텍스트 반환하기
- find_all 메서드 사용 : 찾으려는 태그를 a, 클래스를 collection-item으로 지정하기
- 리스트 반환됨

- 반복문을 활용해 리스트의 각 항목 출력하고 각각에 .text 적용하기

728x90
반응형
'코딩공부 > Data analysis' 카테고리의 다른 글
| (데이터분석) 중복된 값 제거하기 (0) | 2024.05.17 |
|---|---|
| (데이터분석) 웹 페이지 스크래핑 연습문제 (0) | 2024.05.13 |
| (데이터분석) 파이썬의 glob 라이브러리 사용하여 텍스트파일 읽기 (0) | 2024.05.10 |
| (데이터분석) 파이썬의 requests 라이브러리 이용하여 파일 다운로드하기 (0) | 2024.05.10 |
| (데이터분석) 파이썬의 zipfile 이용하여 플랫파일 압축 해제하고 읽기 (0) | 2024.05.09 |
'코딩공부/Data analysis' Related Articles
more



