
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 코드잇
- 경사하강법
- 다항회귀
- 머신러닝
- SQL
- 행렬
- Seaborn
- for반복문
- 오늘도코드잇
- 코딩독학
- 선형회귀
- 영국석사
- 판다스
- 로지스틱회귀
- 코딩공부
- 코드잇 TIL
- HTML
- CSS
- 윈도우함수
- 유학생
- 런던
- 나혼자코딩
- 데이터분석
- 파이썬
- 결정트리
- numpy
- 코드잇TIL
- sql연습문제
- matplotlib
- 코딩
- Today
- Total
영국 척척석사 유학생 일기장👩🏻🎓
(Machine Learning) 모델 평가하기 본문

가설 함수는 세상에 일어나는 상황을 수학적으로 표현한다는 의미에서 '모델'이라고 부릅니다.
1. 모델의 평가
선형 회귀 모델을 학습시켜서, 나름 최적선이라고 생각하는 아래와 같은 가설 함수가 나왔다고 가정해봅시다.
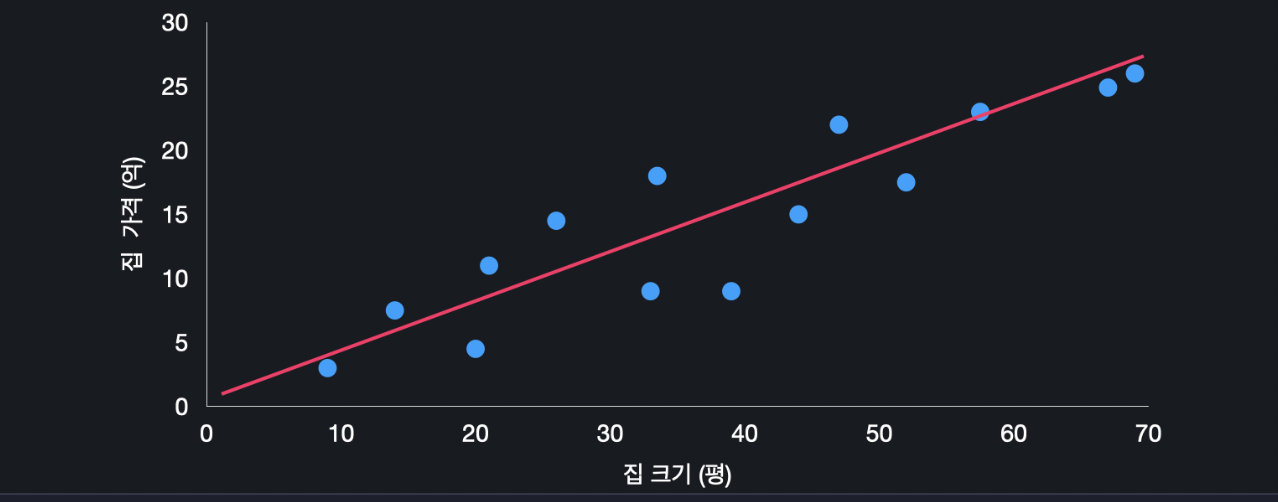
그런데 모델을 학습시키고 나서는 이 모델이 얼마나 좋은지 평가를 해야 합니다. 이 모델이 결과를 얼마나 정확히 예측하는지를 평가해야한다는 것입니다.
2. RMSE
이때 많이 쓰는 게 '평균 제곱근 오차' 영어로는 'root mean square error' 줄여서 'RMSE'라고 합니다. 평균 제곱 오차에 루트를 한 것입니다. 루트를 하는 이유는 만약 우리가 집 가격을 예측한다고 하면, 목표 변수의 단위는 '원'입니다. 그런데 오차 제곱을 하면 단위가 '원 제곱'이 됩니다. 따라서 마지막에 루트를 해서 다시 단위를 '원'으로 만들어 주는 것입니다.
3. Training set, Test set
학습시킨 모델, 즉 우리가 찾은 최적선을 우리 데이터랑 비교해서 평균 제곱근 오차를 구하면 됩니다. 하지만 함정이 있습니다. 우리는 이 데이터에 맞게끔 모델을 학습시켰으니까 평균 제곱근 오차가 낮게 나오는건 어떻게 보면 너무 당연한 것입니다. 신빙성 있게 모델을 평가하는 방법을 알아봅시다. 보통은 모델을 학습시키기 위한 데이터와 모델을 평가하기 위한 데이터를 따로 분리합니다.
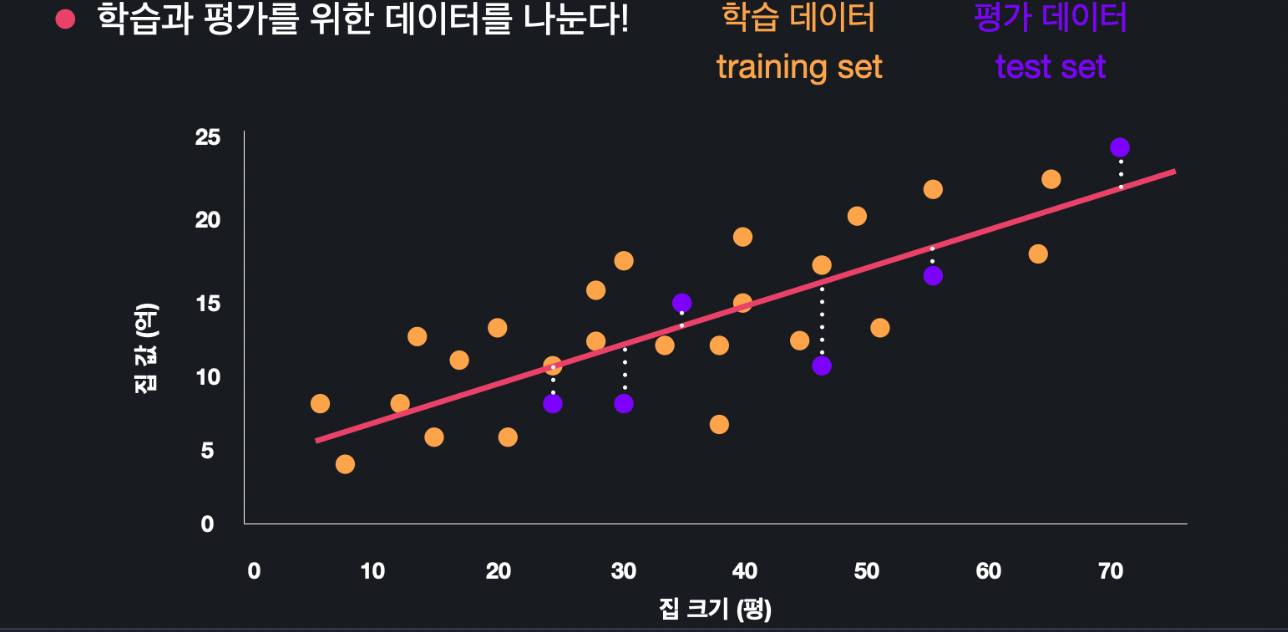
데이터가 이렇게 30개가 있다고 가정합시다. 그러면 이 30개를 다 학습시키기 위해 사용하는게 아니라 24개, 6개 등 나눕니다. 24개는 모델을 학습시키기 위해 쓰고, 6개는 모델을 평가하기 위해 쓰는 것입니다. 모델을 학습시키기 위해 쓰는 데이터셋을 'training st'이라고 하고 모델을 평가하기 위해 쓰는 데이터셋을 'test set'이라고 합니다.
따라서 우선 training set의 24개 주황색 데이터를 통해 모델을 학습시켜서, 이 데이터에 가장 잘 맞는 최적선을 구합니다. 그러고 나서 이 최적선을 training set이 아닌 test set의 보라색 데이터 6개와 놓고 평가하는 것입니다. 위의 경우에는 평균 제곱근 오차를 계산해서 평가하는 것입니다. 이렇게 하면 학습에 사용된 데이터와 평가에 사용된 데이터가 따로니까, 좀 더 신빙성 있게 우리의 모델을 평가할 수 있게 되는 것입니다.
'코딩공부 > Machine Learning' 카테고리의 다른 글
| (Machine Learning) 다중 선형 회귀 가설 함수 (0) | 2023.08.21 |
|---|---|
| (Machine Learning) 다중 선형 회귀 (0) | 2023.08.21 |
| (Machine Learning) 학습률 알파 (0) | 2023.08.09 |
| (Machine Learning) 선형 경사 하강법 구현하기 (0) | 2023.07.12 |
| (Machine Learning) 경사 하강법 계산 (0) | 2023.07.11 |



