
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 코드잇 TIL
- 결정트리
- CSS
- 데이터분석
- 머신러닝
- 파이썬
- 행렬
- pandas
- 코딩
- 코딩공부
- HTML
- Seaborn
- SQL
- 코딩독학
- 서브쿼리
- 코드잇
- 오늘도코드잇
- 코드잇TIL
- 나혼자코딩
- 판다스
- 경사하강법
- for반복문
- sql연습문제
- matplotlib
- numpy
- 로지스틱회귀
- 선형회귀
- 다항회귀
- 메소드
- 윈도우함수
Archives
- Today
- Total
Coding Diary.
(데이터분석) 이변량 차트를 seaborn의 hue이용해서 다변량 차트 나타내기 본문
728x90
반응형
이번 글에서는 이변량 차트의 응용 방법에 대해 알아보겠습니다.
1. 차급과 변속기 종류에 따른 다변량 연비 차트
- 먼저 필요한 라이브러리를 불러오고 연비 데이터 세트를 가져오고 변속기 종류를 추출하겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsdf = pd.read_csv('../data/fuel-econ/csv')
df['trans_type'] = df['trans'].apply(lambda x:x.split()[0])- seaborn 차트에 색상을 추가할 때는 매개변수 hue를 추가하면 됩니다.
sns.pointplot(data=df, x='VClass', y='comb',
hue='trans_type', errorbar='sd', linestyle="", dodge=True);
plt.xticks(rotation = 15)
plt.ylabel('Avg. Combined Fuel Efficiency (mpg)')'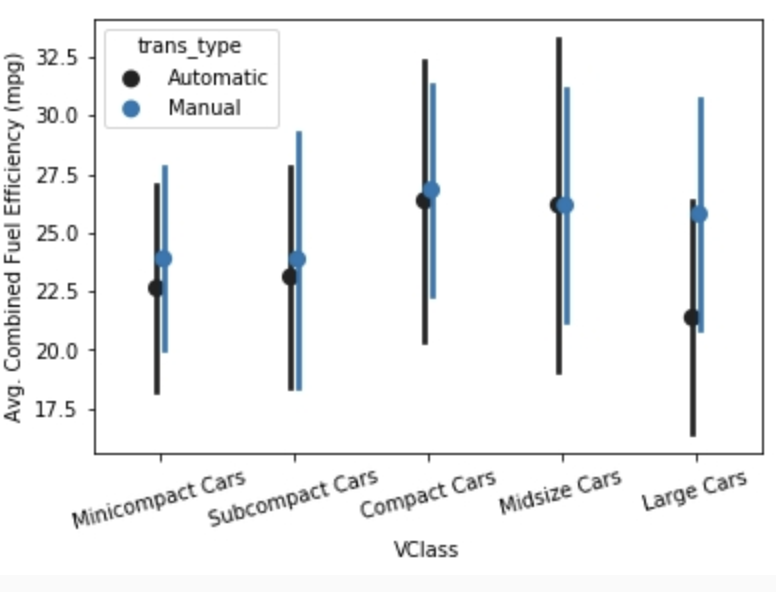
2. 병렬 막대 그래프 (Clusterd bar chart)
- 병렬 막대 그래프도 seaborn에 hue 매개변수를 추가하여 같은 방법으로 만들 수 있습니다.
# 위의 코드로 작성한 차급과 변속기 종류에 따른 연비를 나타내는 병렬 막대 그래프
sns.barplot(data=df, x='VClass', y='comb', hue='trans_type', errorbar='sd');
plt.xticks(rotation = 15)
plt.ylabel('Avg. Combined Fuel Efficiency (mpg)');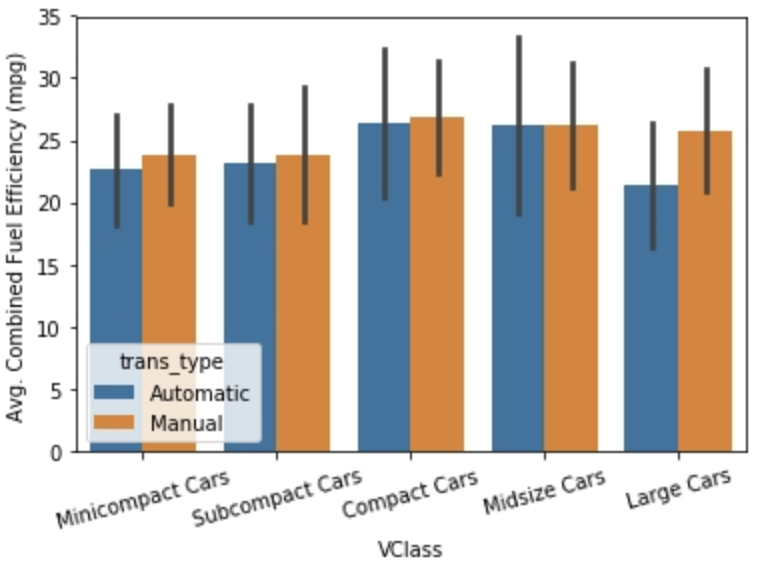
🔻(참고)병렬막대차트🔻
(데이터분석) seaborn으로 병렬 막대 차트(Clustered bar chart), 히트맵(heatmap)그리기
단변량 막대 그래프 그리는 방법에 이어 병렬 막대 그래프 그리는 방법에 대해 알아보겠습니다. 🔻(지난글) 단변량 막대그래프🔻 (데이터분석) 불연속 데이터에서의 히스토그램, 막대그래프
life-of-nomad.tistory.com
3. 병렬 상자 그림 (Clusterd box chart)
- 같은 방법으로 병렬 상자 그림도 작성할 수 있습니다.
#차급과 변속기 종류에 따른 연비를 나타내는 병렬 상자 그림
sns.boxplot(data=df, x='VClass', y='comb', hue='trans_type');
plt.xticks(rotation = 15)
plt.ylabel('Avg. Combined Fuel Efficiency (mpg)')
🔻(참고)상자그림🔻
(데이터분석) seaborn으로 상자 그림(box plot) 나타내기
지난 글에서 숫자 데이터와 범주형 데이터 사이의 관계를 표현할 수 있는 바이올린 플롯에 대해 알아보았습니다.이번 글에서는 숫자 데이터와 범주형 데이터 사이의 관계를 나타내는 또 다른
life-of-nomad.tistory.com
4. 히트맵
- 2차원 히스토그램인 히트맵도 변형할 수 있습니다.
- 이를 통해 색상으로 각 셀의 도수가 아니라 세 번째 변수의 평균을 나타낼 수 있습니다.
- 먼저, 복합 연비와 엔진 배기량으로 구성된 이차원 히스토그램을 작성해보겠습니다.
- 색상으로는 각 셀의 도수를 나타내겠습니다.
- 색상을 입힐 셀의 최소값을 0.5로 지정하고 색상 팔레트도 선택합니다.
bins_x = np.arange(0.6, 7+0.3, 0.3)
bins_y = np.arnage(12, 58+3, 3)
plt.hist2d(data=df, x='displ', y='comb', cmin=0.5,
cmap='viridis_r', bins=[bins_x, bins_y]);
plt.xlabel('Displacement (1)')
plt.ylabel('Combined Fuel Eff (mpg)');
plt.colorbar(label='Number of counts');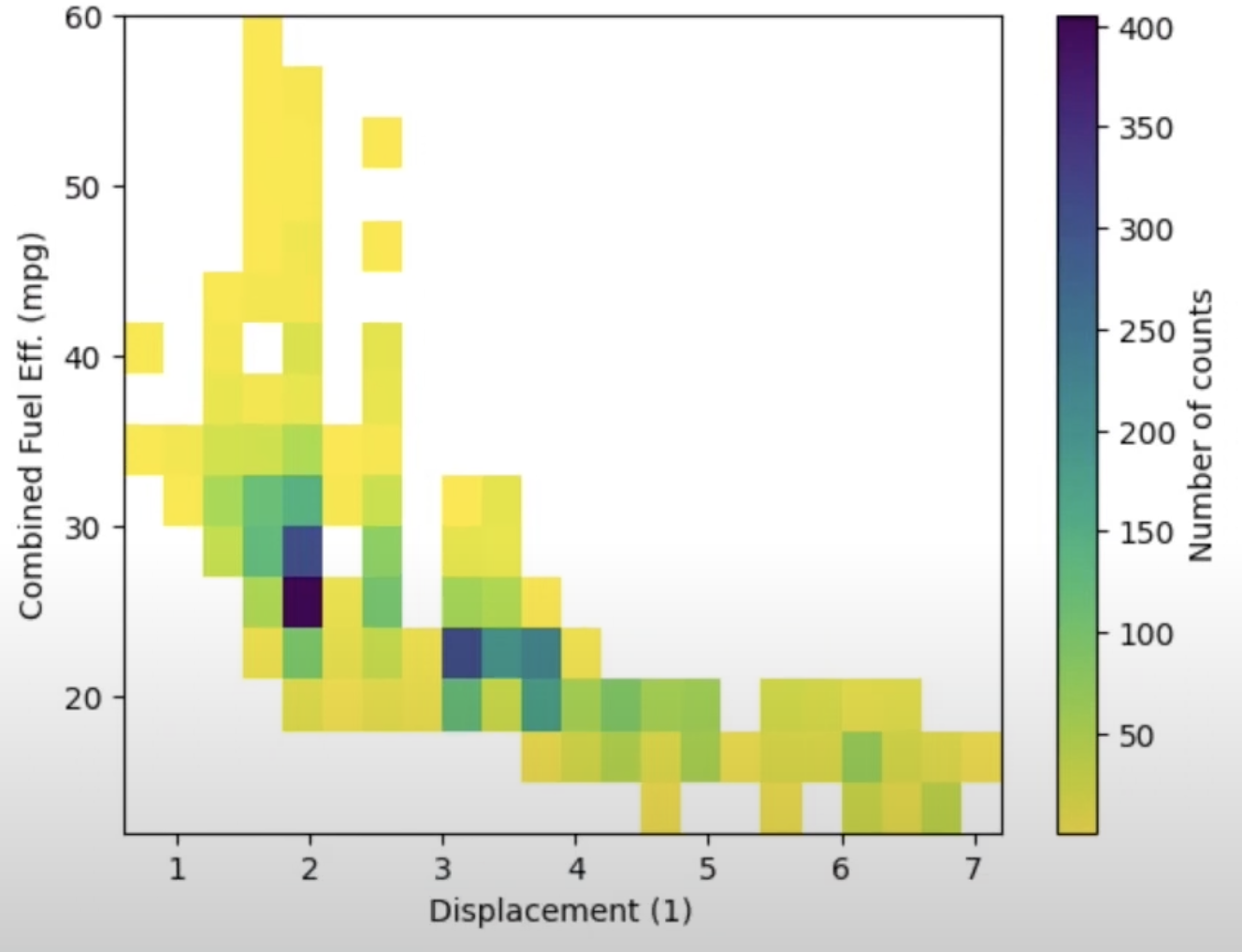
- 연비와 배기량을 나타내며 색상은 각 셀의 도수를 나타내는 2차원 히스토그램이 완성되었습니다.
- 이제 색상이 각 셀의 평균 이산화탄소 배출량을 나타내도록 변경해보겠습니다.
- 이를 위해서는 hist2d 함수에서 가중치를 의미하는 매개변수 weights를 사용해야 합니다.
- 기본적으로 각 점의 가중치는 1이며, 색상은 해당 셀에 속하는 점들의 가중치 합으로 결정됩니다.
- 만약, 각 점의 co2 배출량을 해당 점이 속하는 셀의 차량 숫자로 나눈 값을 각 점의 가중치로 설정한다면 각 셀의 가중치 합은 각 셀의 평균 co2 배출량이 됩니다.
# 각 데이터 포인트의 계급 결정하기(각 점이 어느 셀에 속하는지 파악)
#pandas.cut(dataframe의 series또는 배열, 계급크기).astype(데이터유형 정수로 바꿈)
disple_bins = pd.cut(df['displ'], bins_x, right=False,
include_lowest=False, labels=False).astype(int)
comb_bins = pd.cut(df['comb'], bins_y, right=False,
include_lowest=False, labels=False).astype(int)- 이어서 각 계급에 속하는 점의 개수를 구합니다.
# 각 계급에 속하는 데이터 포인트의 개수 구하기
# 배기량과 연비의 계급 크기에 대해 groupby문 사용
n_points = df.groupby([displ_bins, comb_bins]).size()
# pivot 매서드를 사용해 결과를 2차원 배열로 만듦
# values 속성을 사용해 점의 개수로 구성된 배열 만듦
n_points = n_points.reset_index().pivot(index = 'displ', column='comb').values- 이 값들을 사용해서 각 점의 가중치를 구할 수 있습니다.
- co2 series를 가져와서 그 안의 각 요소를 각 셀에 속하는 점의 개수로 나눕니다.
# co2를 각 계급에 속하는 데이터 포인트의 개수로 나누기
co2_weights = df['co2'] / n_points[displ_bins, comb_bins]
#그 결과를 hist2d 함수의 매개변수 weights에 전달
plt.hist2d(data=df, x='displ', y='comb', cmin=0.5,
cmap='viridis_r', bins=[bins_x, bins_y], weights=co2_weights);
plt.xlabel('Displacement (1)')
plt.ylabel('Combined Fuel Eff. (mpg)');
plt.colorbar(label = 'CO2 (g/mi)');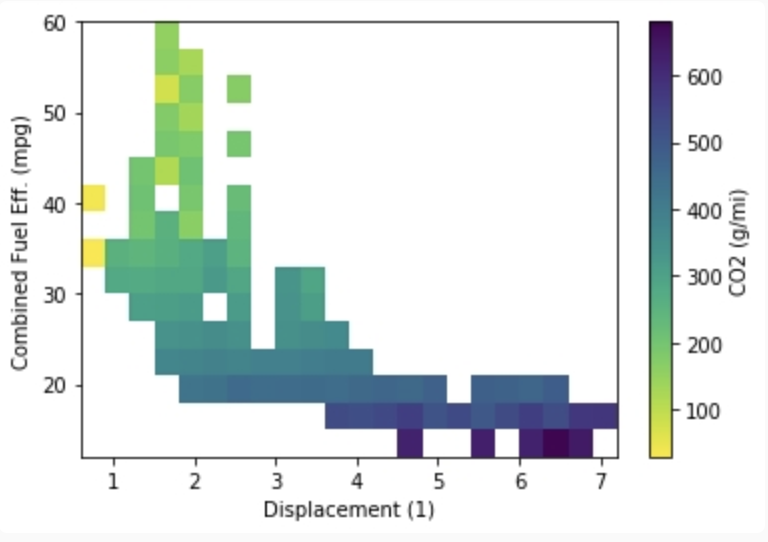
- 결과를 보면 엔진이 커질수록 연비는 떨어지며 co2 배출량은 급증한다는 걸 알 수 있습니다.
🔻(참고)히트맵🔻
(데이터분석) matplotlib으로 heatmap(히트맵) 작성하기
1. 히트맵히트맵은 일종의 이차원 히스토그램으로 산점도를 대체할 수 있는 차트입니다.두 숫자 변수의 값들이 두 개의 축을 기준으로 평면에 표시된다는 점에서 산점도와 유사합니다.한편, 데
life-of-nomad.tistory.com
728x90
반응형
'Coding > Data analysis' 카테고리의 다른 글
| (데이터분석) seaborn의 pairgrid 함수 이용해서 차트행렬 (Plot Matrices) 작성하기 (1) | 2024.05.29 |
|---|---|
| (데이터분석) 다변량 데이터에서 Faceting(면 분할)하기 (0) | 2024.05.29 |
| (데이터분석) matplotlib,seaborn에서 마커를 이용하여 다변량 변수 나타내기 (1) | 2024.05.28 |
| (데이터분석) matplotlib으로 선도표 나타내기 (0) | 2024.05.28 |
| (데이터분석) seaborn으로 히스토그램 faceting(면 분할) 하기 (0) | 2024.05.27 |
'Coding/Data analysis' Related Articles
more



